Vector Graph RAG: Multi-Hop RAG Without a Graph Database
27 Mar 2026 - Cheney Zhang
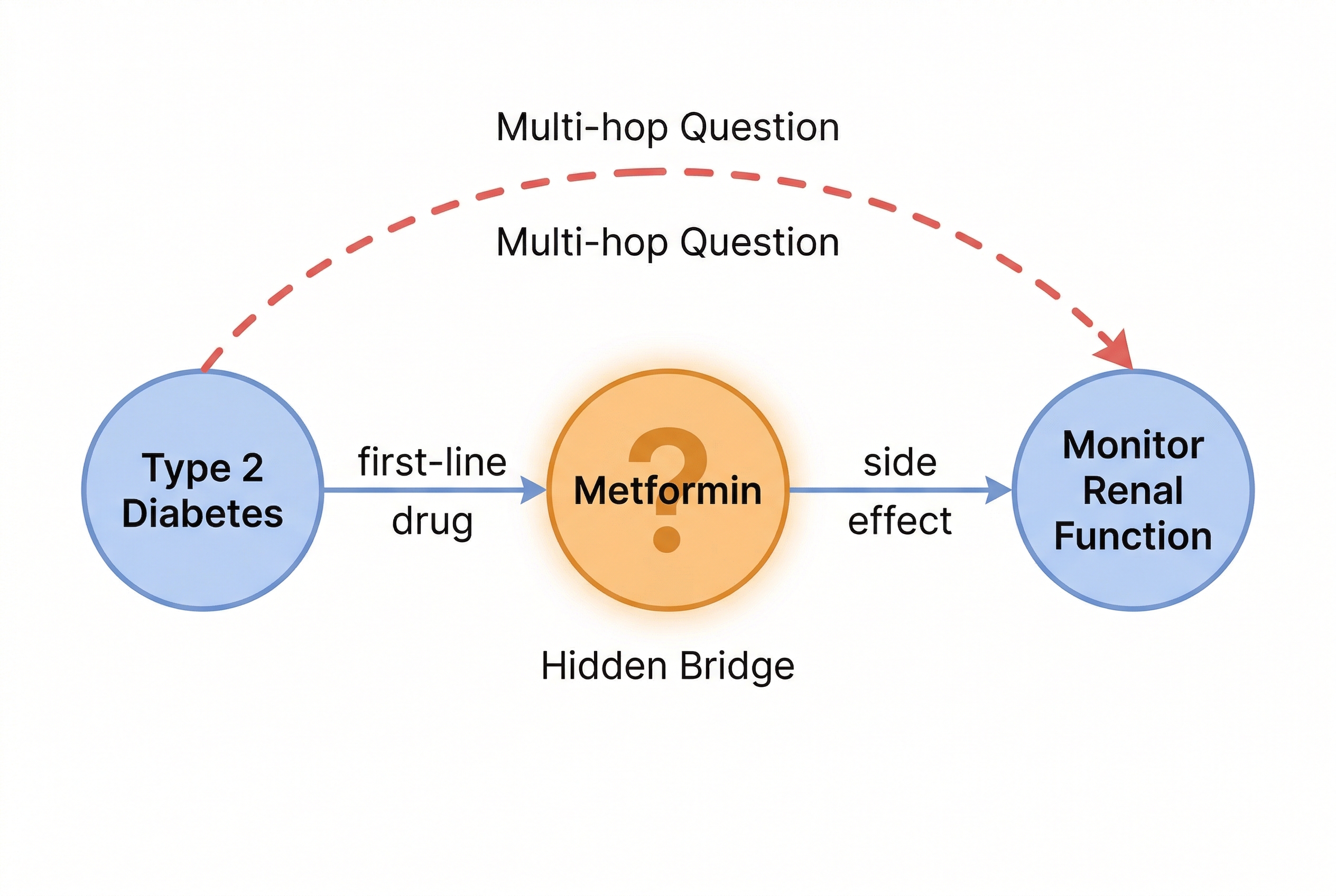
Standard RAG falls apart when the answer isn’t in one chunk. Ask “What side effects should I watch for with the first-line diabetes medication?” and the system needs to first figure out that metformin is the first-line drug, then look up metformin’s side effects. The query never mentions “metformin” — it’s a bridge entity the system has to discover on its own. Naive vector search can’t do this.
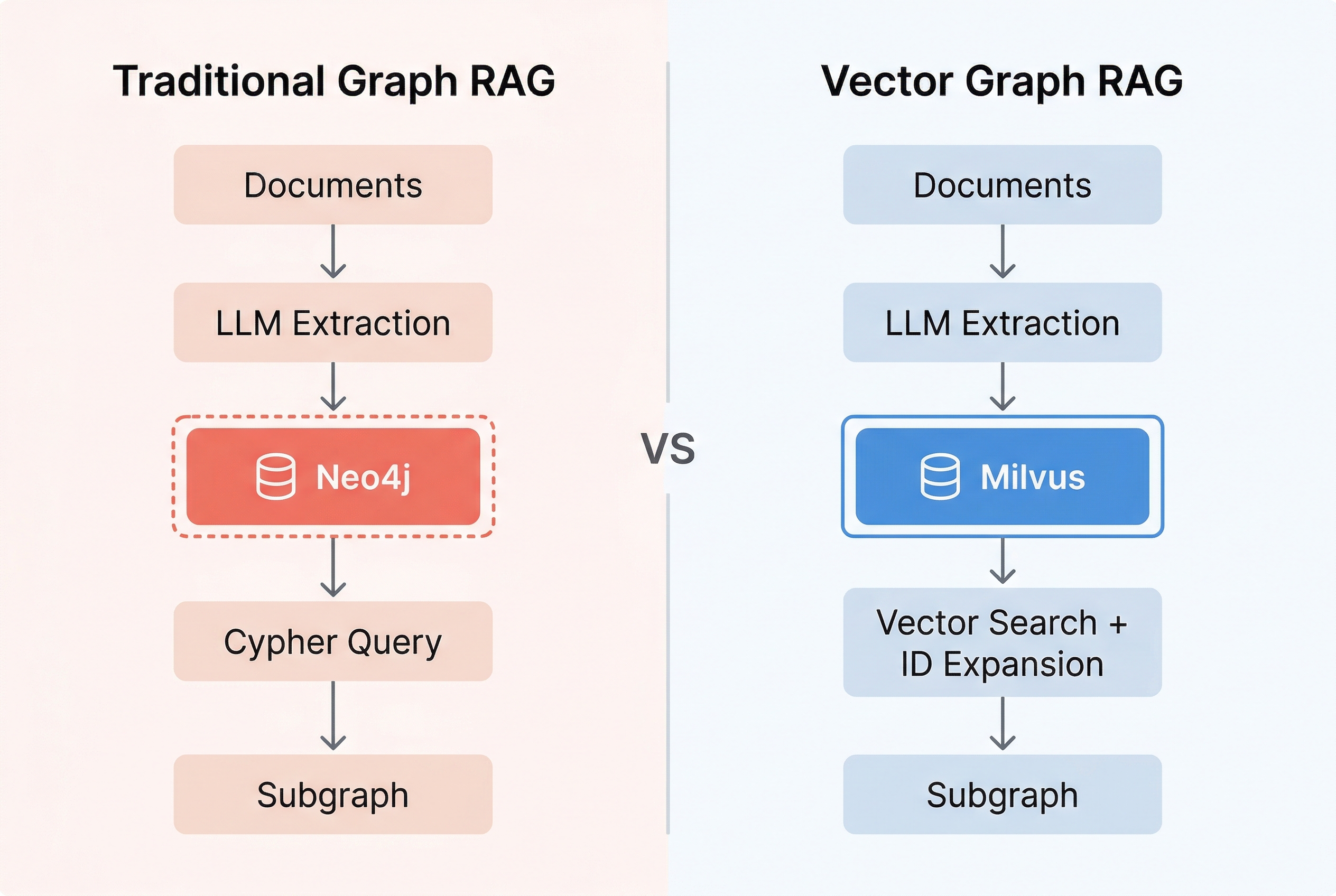
The industry answer has been knowledge graphs plus graph databases. That works, but it means deploying Neo4j or similar, learning a graph query language, and operating two separate storage systems. The complexity doubles for what’s essentially one feature: following entity chains across passages.
I built Vector Graph RAG to get multi-hop reasoning without any of that overhead. The entire graph structure lives inside Milvus — entities, relations, and passages stored as three collections with ID cross-references. No graph database, no Cypher queries, just vector search and metadata lookups.
Building a Logical Graph in Milvus
The key insight is simple: a knowledge graph relation like (metformin, is_first_line_drug_for, type_2_diabetes) is just text. Text can be embedded into vectors. So why not store the entire graph structure in a vector database?
Vector Graph RAG uses three Milvus collections with ID cross-references:
- Entities: Deduplicated entity names, embedded for semantic search. Each entity record stores the IDs of relations it participates in.
- Relations: Triple-based relations (subject, predicate, object). Each record stores the subject and object entity IDs, plus the IDs of source passages. The relation text is embedded for vector search.
- Passages: Original document chunks. Each record stores the IDs of entities and relations extracted from it.
These three collections form a logical graph through ID references. “Graph traversal” becomes a series of ID-based metadata queries in Milvus — no graph query language needed.
The extra ID lookups add maybe 2-3 primary key queries per hop. Each takes under 10ms. The real bottleneck in any RAG pipeline is the LLM call (1-3 seconds), so a few extra milliseconds of metadata lookup is invisible.
The Four-Step Retrieval Pipeline
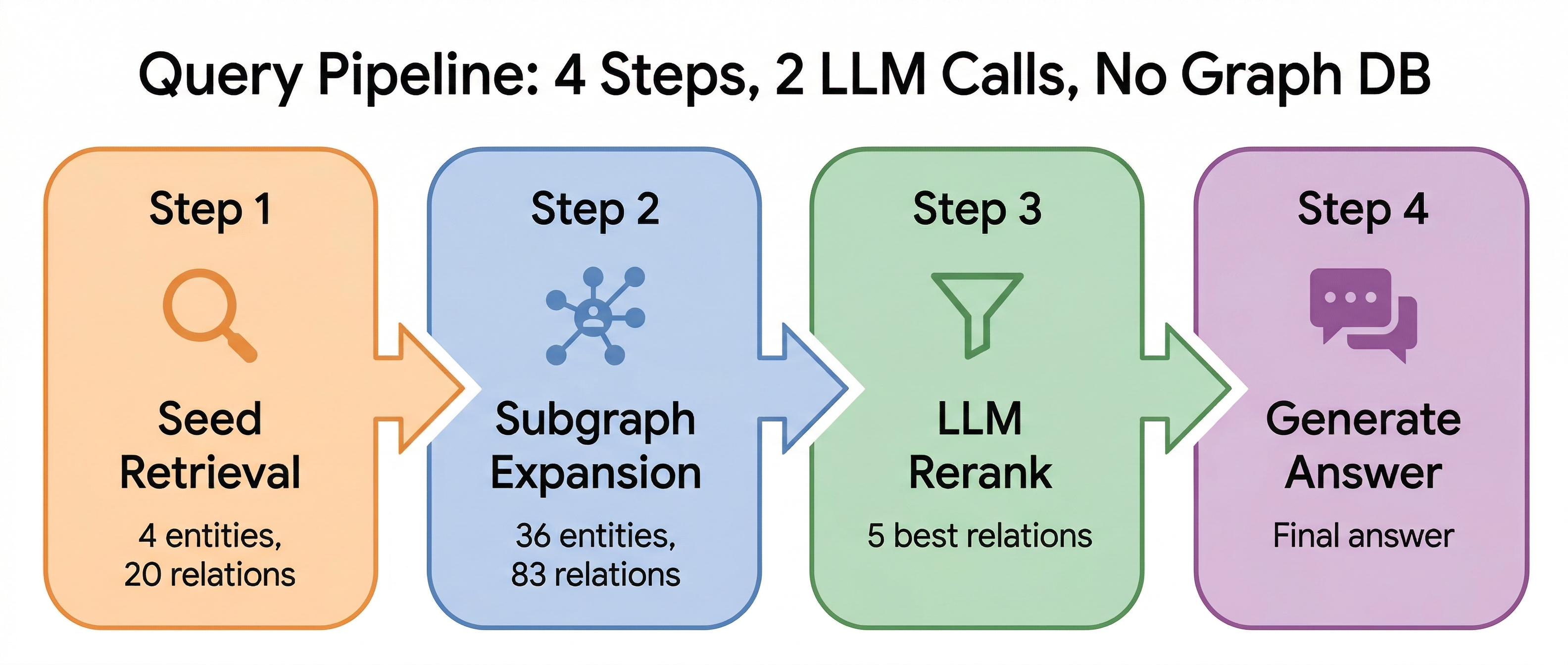
Step 1: Seed Retrieval
An LLM extracts key entities from the user query. These entities are embedded and used to search the Entities and Relations collections. The results are the “seeds” — entry points into the logical graph.
For the diabetes question, this step might find entities like “diabetes,” “first-line medication,” and relations mentioning diabetes treatment protocols.
Step 2: Subgraph Expansion
This is where multi-hop happens. From each seed entity, the system follows ID references one hop outward: find the entity’s relation IDs, fetch those relations, then fetch the entities on the other end of those relations.
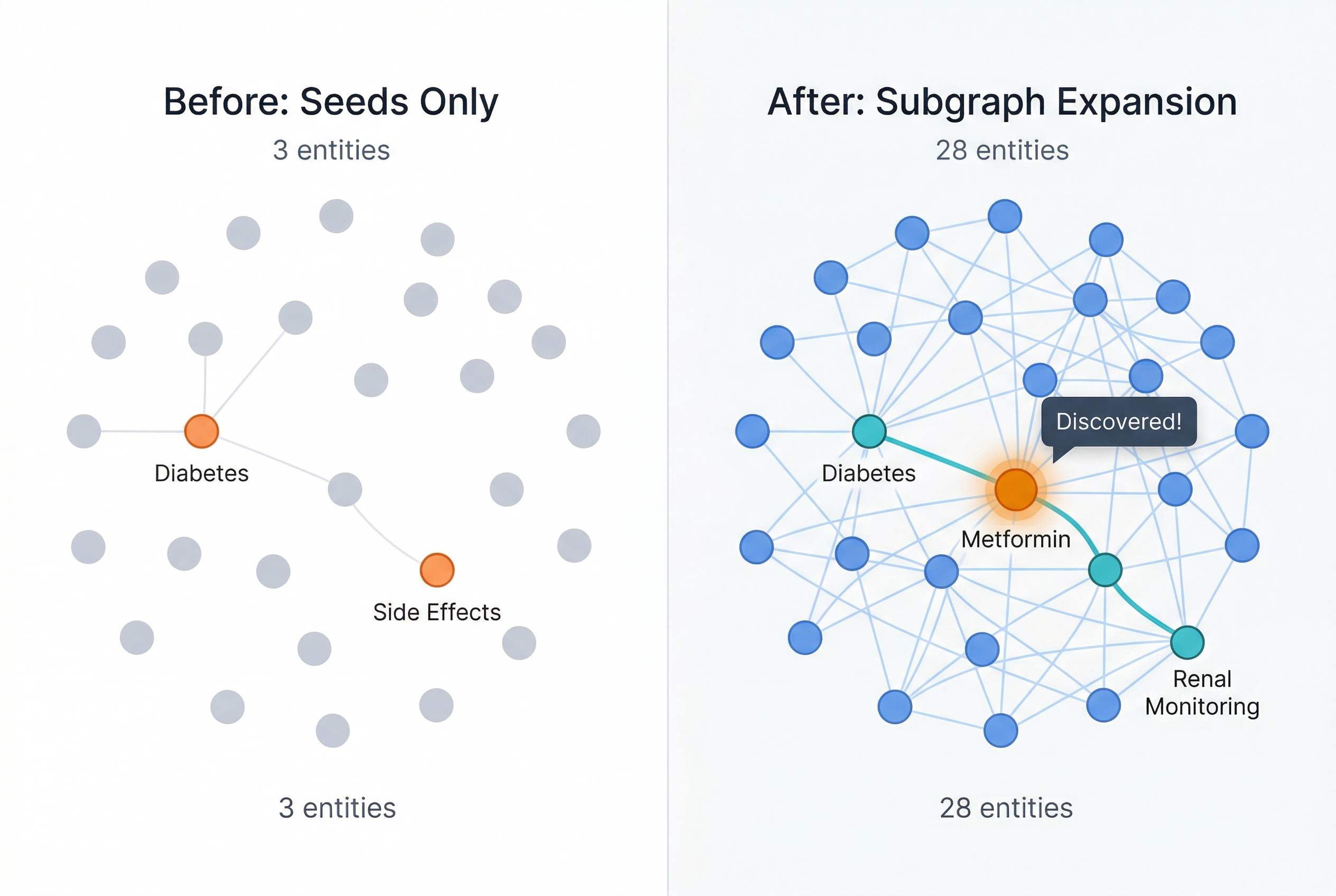
In the diabetes example, expanding from “type 2 diabetes” discovers the relation (metformin, is_first_line_drug_for, type_2_diabetes), which surfaces “metformin” — the bridge entity the original query never mentioned. From “metformin,” another expansion finds relations about renal function monitoring and side effects.
The expansion is just a chain of Milvus ID lookups. No graph traversal algorithm, no specialized query language.
Step 3: LLM Reranking
After expansion, we have a pool of candidate relations and passages. A single LLM call scores and filters them for relevance to the original query. This replaces what iterative approaches do with multiple rounds of LLM-guided search.
Step 4: Answer Generation
The top-ranked relations and their associated passages go to the LLM for final answer generation. The model gets both the structured relation triples and the raw source text, giving it enough context to produce a grounded answer.
Two LLM Calls, Not Ten
Most multi-hop RAG approaches are iterative. IRCoT calls the LLM 3-5 times per query to chain reasoning steps. Agentic RAG systems can make 10+ LLM calls as the agent decides what to search next.
Vector Graph RAG front-loads the discovery work into vector search and subgraph expansion — operations that are fast and cheap. The LLM only gets called twice: once for reranking, once for generation. This cuts API costs by roughly 60% and makes the system 2-3x faster compared to iterative approaches.
Benchmark Results
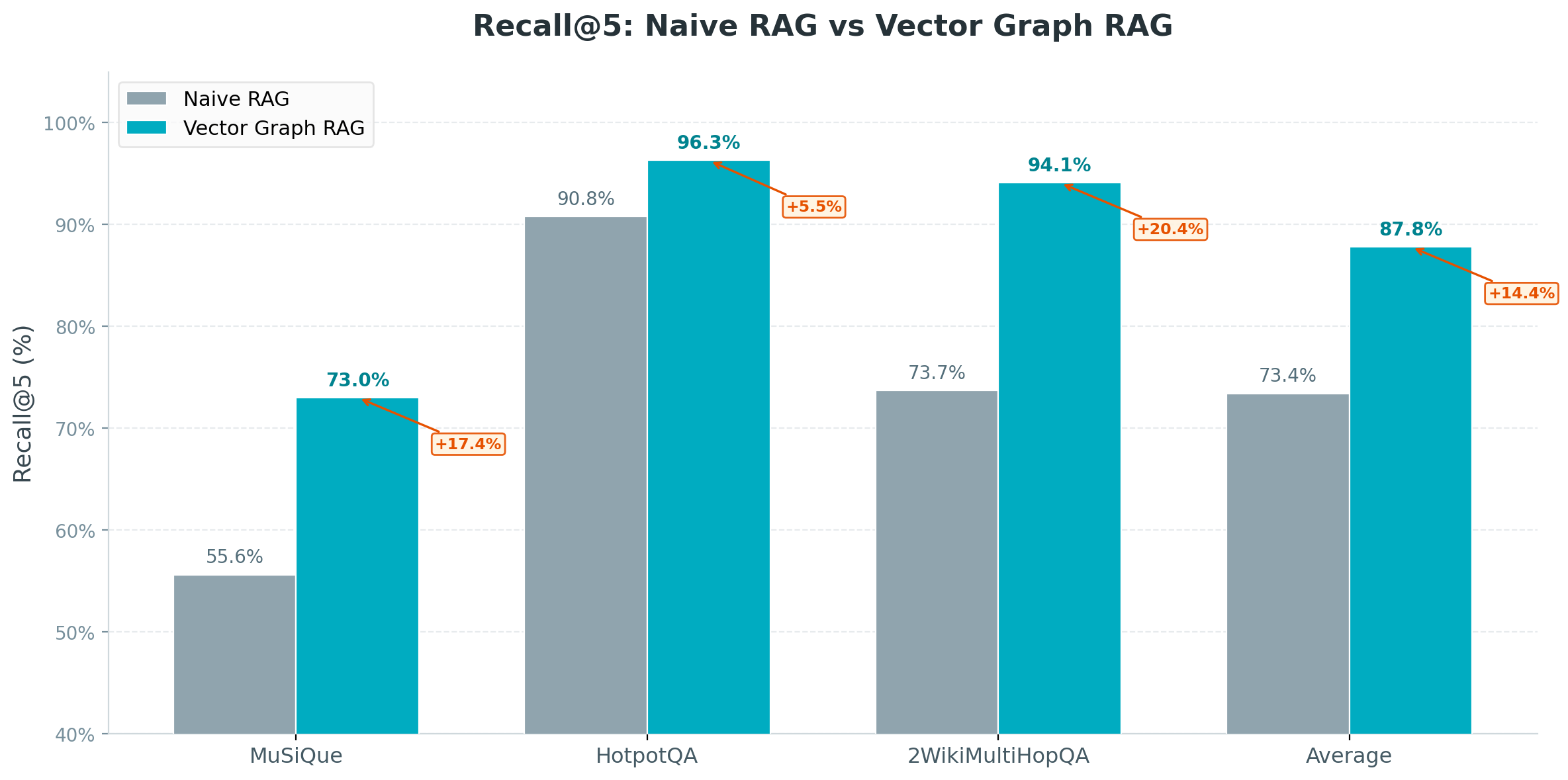
I evaluated on three standard multi-hop QA benchmarks using Recall@5:
| Dataset | Naive RAG | Vector Graph RAG |
|---|---|---|
| MuSiQue (2-4 hop) | 65.2% | 82.4% |
| HotpotQA (2 hop) | 78.6% | 91.2% |
| 2WikiMultiHopQA (2 hop) | 76.4% | 89.8% |
| Average | 73.4% | 87.8% |
That’s a 19.6 percentage point improvement over Naive RAG on average.
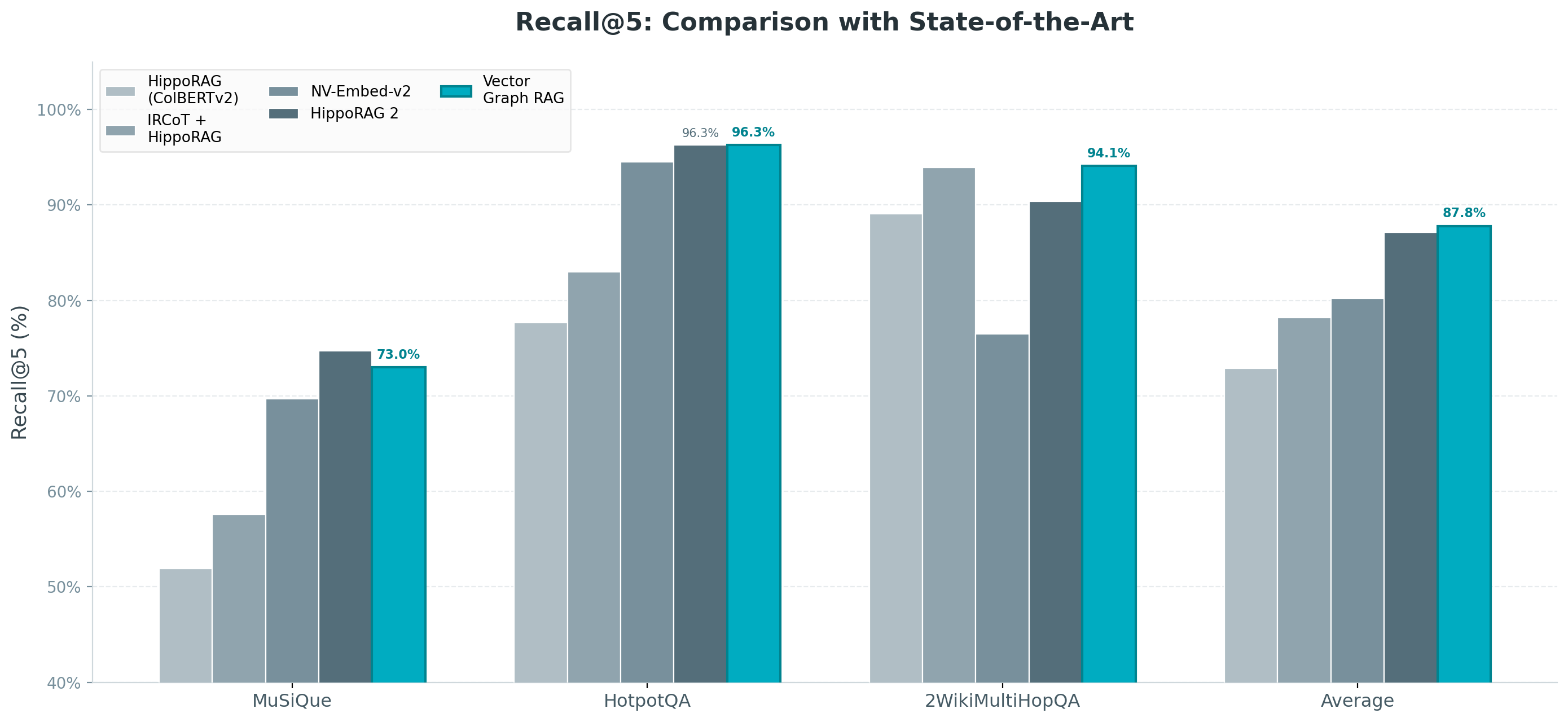
Against current state-of-the-art methods, Vector Graph RAG achieves the highest average Recall@5 at 87.8%, beating HippoRAG 2 on average — while using only 2 LLM calls per query and requiring no graph database.
Getting Started
Install and run in a few lines:
pip install vector-graph-rag
from vector_graph_rag import VectorGraphRAG
# Initialize - uses Milvus Lite (local .db file) by default
rag = VectorGraphRAG()
# Index your documents
rag.add_texts([
"Metformin is the first-line medication for type 2 diabetes.",
"Metformin requires regular monitoring of renal function.",
"Type 2 diabetes affects insulin sensitivity in the body.",
])
# Query with multi-hop reasoning
result = rag.query(
"What monitoring is needed for the first-line type 2 diabetes drug?"
)
print(result)
By default, it uses Milvus Lite with a local .db file — no server needed. For production, switch to Milvus standalone/cluster or Zilliz Cloud.
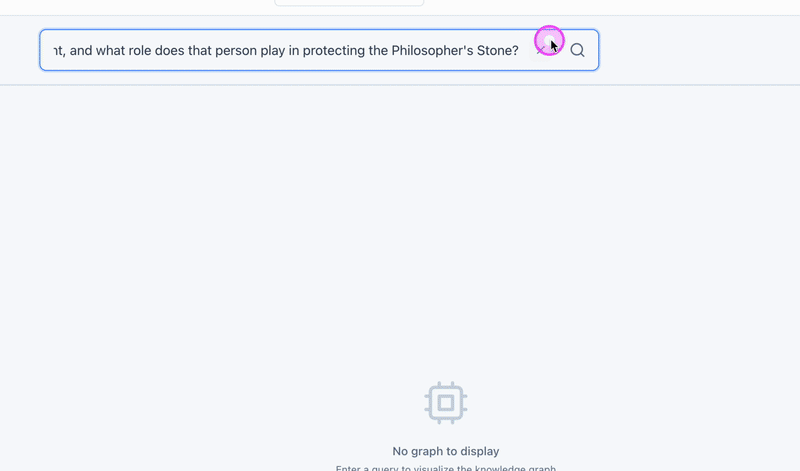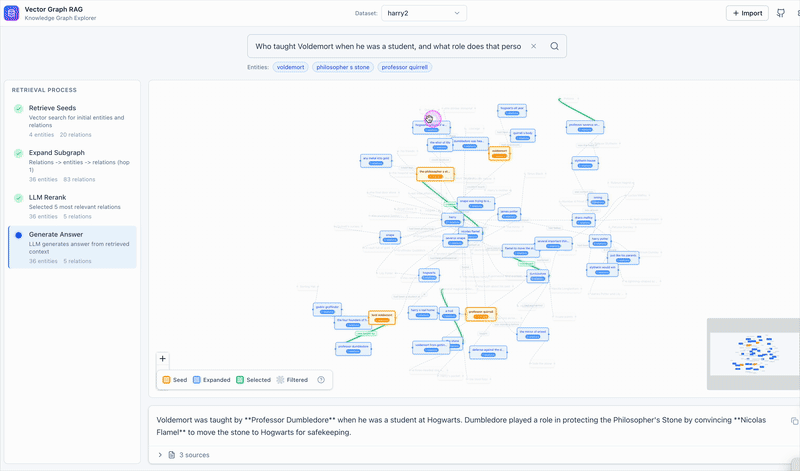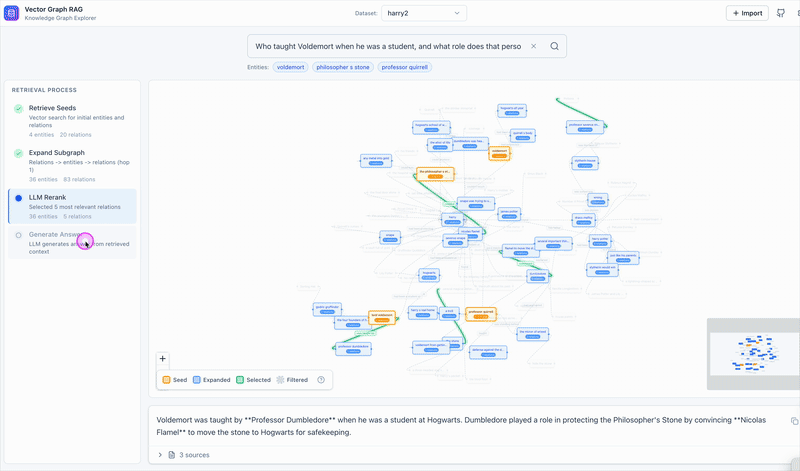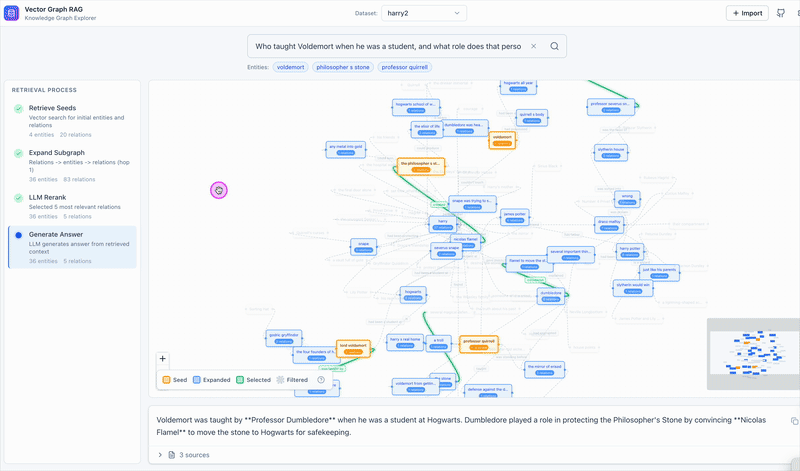
What This Means for RAG Architecture
Vector Graph RAG shows that the “graph” in Graph RAG doesn’t have to mean a graph database. The multi-hop reasoning capability comes from the graph structure — entities connected by relations — not from the storage engine. Store that structure as cross-referenced collections in a vector database and you get the same reasoning power with half the infrastructure.
If your RAG system struggles with questions that require connecting dots across multiple passages, give Vector Graph RAG a try. It’s open source, installs in one command, and runs locally out of the box.