Which Embedding Model Should You Actually Use in 2026? I Benchmarked 10 Models to Find Out
20 Mar 2026 - Cheney Zhang
Still using OpenAI’s text-embedding-3-small without a second thought? If you’re building RAG or vector search systems, you’ve probably noticed that new embedding models drop every few weeks, each claiming SOTA on some leaderboard. But when it comes to picking one for production, those MTEB scores don’t always translate to real-world performance.
On March 10, 2026, Google released Gemini Embedding 2 Preview — a model that supports five modalities (text, image, video, audio, PDF) natively, 100+ languages, native MRL (Matryoshka Representation Learning), and 3072-dimensional output. On paper, it checks every box.
The official benchmarks look impressive too:
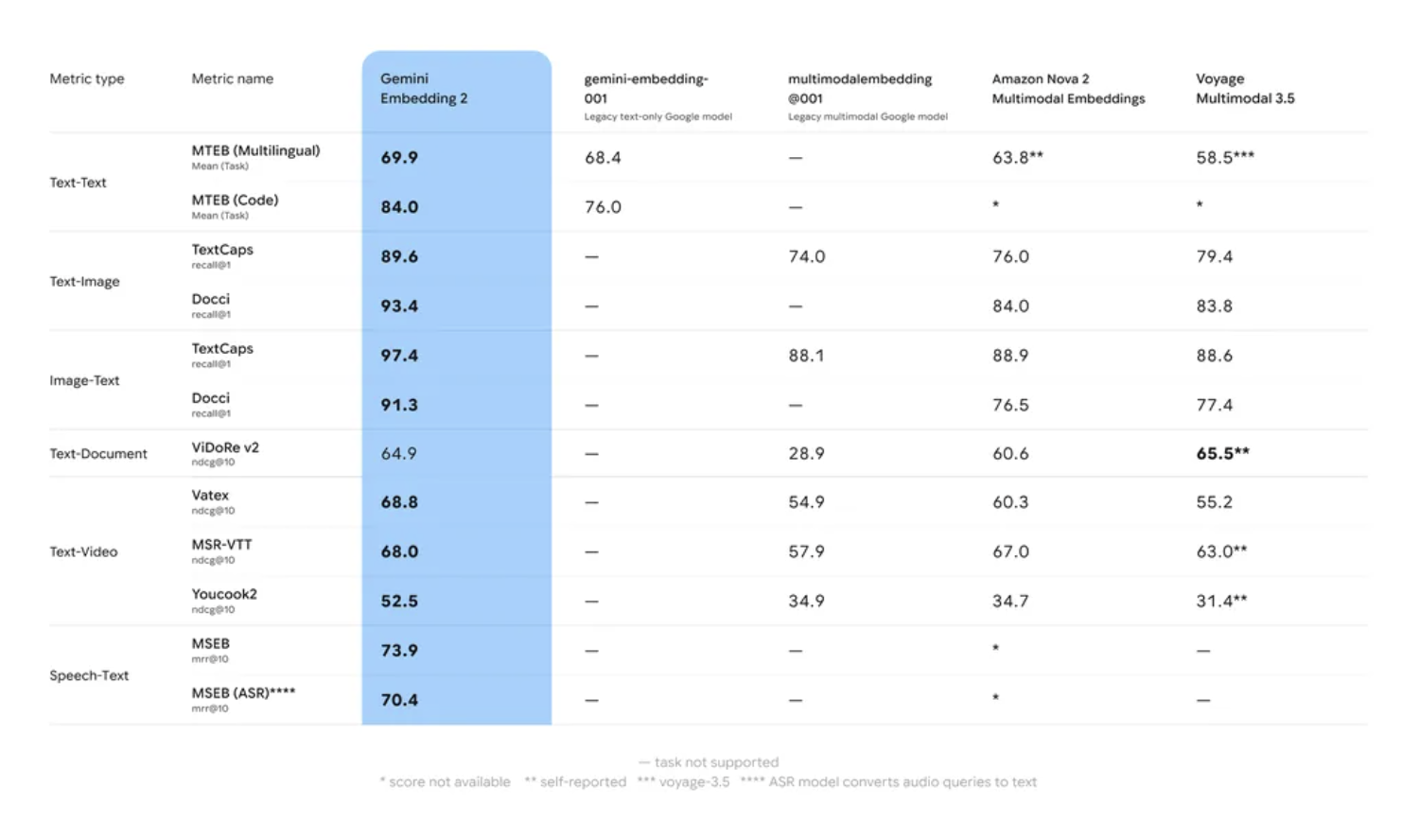
But official benchmarks tend to highlight the best scenarios. So I decided to test things myself: pick a batch of 2025-2026 models and run them through tasks that public benchmarks don’t cover well.
The Contenders
I selected 10 models spanning API services and open-source local deployment, plus classic baselines like OpenAI text-embedding-3-large and CLIP ViT-L-14.
| Model | From | Params | Dims | Modalities | Notes |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Unknown | 3072 | Text/Image/Video/Audio/PDF | All-modality universal | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | Text/Image/PDF | MRL + LoRA multi-task |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | Unknown | 1024 | Text/Image/Video | Balanced across the board |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Text/Image/Video | Open-source, lightweight multimodal |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Text/Image | Modern CLIP architecture |
| Cohere Embed v4 | Cohere | Unknown | Fixed | Text | Enterprise retrieval |
| OpenAI 3-large | OpenAI | Unknown | 3072 | Text | Most widely used |
| BGE-M3 | BAAI | 568M | 1024 | Text | Open-source multilingual |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Text | Lightweight, English-focused |
| nomic-embed-text | Nomic AI | 137M | 768 | Text | Ultra-lightweight |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Text/Image | Classic baseline |
A quick rundown of the newer ones:
Gemini Embedding 2 is Google’s first all-modality embedding model, released March 2026, supporting all five modalities.

Jina Embeddings v4 is built on Qwen2.5-VL-3B (3.8B params). It uses three LoRA adapters (retrieval.query / retrieval.passage / text-matching) to switch between retrieval scenarios. Supports text, images, and PDFs.

Jina CLIP v2 is Jina AI’s modernized CLIP architecture focused on text-image cross-modal alignment with multilingual support.
Voyage Multimodal 3.5 comes from Voyage AI, acquired by MongoDB for $220M in February 2025. Supports text, images, and video.

Qwen3-VL-Embedding is Alibaba Qwen’s open-source multimodal embedding series (2B and 8B variants). I tested the 2B version since it fits on a single 11GB consumer GPU — a good test of lightweight deployment viability.
Cohere Embed v4 and OpenAI 3-large are text-only stalwarts, regulars on MTEB leaderboards and the most common choices for RAG.

BGE-M3 from BAAI is an open-source multilingual model (568M params, 100+ languages) — the benchmark in Chinese open-source embeddings.
mxbai-embed-large (335M) and nomic-embed-text (137M) are lightweight open-source options. mxbai excels at English MRL, while nomic is the smallest model in this benchmark.
Why Existing Benchmarks Aren’t Enough
Before designing my tests, I looked at what’s already out there and found gaps.
MTEB (Massive Text Embedding Benchmark) is the gold standard, but it’s text-only, doesn’t test cross-lingual retrieval (e.g., Chinese query → English document), doesn’t evaluate MRL dimension truncation, and has limited coverage of truly long documents (10K+ tokens).
MMEB (Massive Multimodal Embedding Benchmark) adds multimodal, but lacks hard negatives — distractors are too easy, making it hard to differentiate models on fine-grained understanding.
Neither tests cross-lingual retrieval, MRL compression quality, or long-document needle retrieval. These happen to be exactly the pain points developers face when building RAG / Agent / vector search systems. So I designed four evaluation tasks: cross-modal retrieval, cross-lingual retrieval, needle-in-a-haystack, and MRL dimension compression.
Evaluation Tasks and Results
Round 1: Cross-Modal Retrieval (Text ↔ Image)
Scenario: E-commerce visual search, multimodal knowledge bases, multimedia content understanding.
Task design: 200 image-text pairs from COCO val2017. Text descriptions generated by GPT-4o-mini, each image paired with 3 hard negatives — descriptions that differ from the correct one by just one or two details. Models must retrieve correctly from a pool of 200 images + 600 distractor descriptions.
Here’s an actual sample from the dataset:

Correct description: “The image features vintage brown leather suitcases with various travel stickers including ‘California’, ‘Cuba’, and ‘New York’, placed on a metal luggage rack against a clear blue sky.”
Hard negatives (single keyword swaps):
- leather suitcases → canvas backpacks
- California → Florida
- metal luggage rack → wooden shelf
The model must truly understand visual details to distinguish these hard negatives.
Scoring: Bidirectional R@1 — text-to-image and image-to-text, averaged as hard_avg_R@1.
Results
This one surprised me.
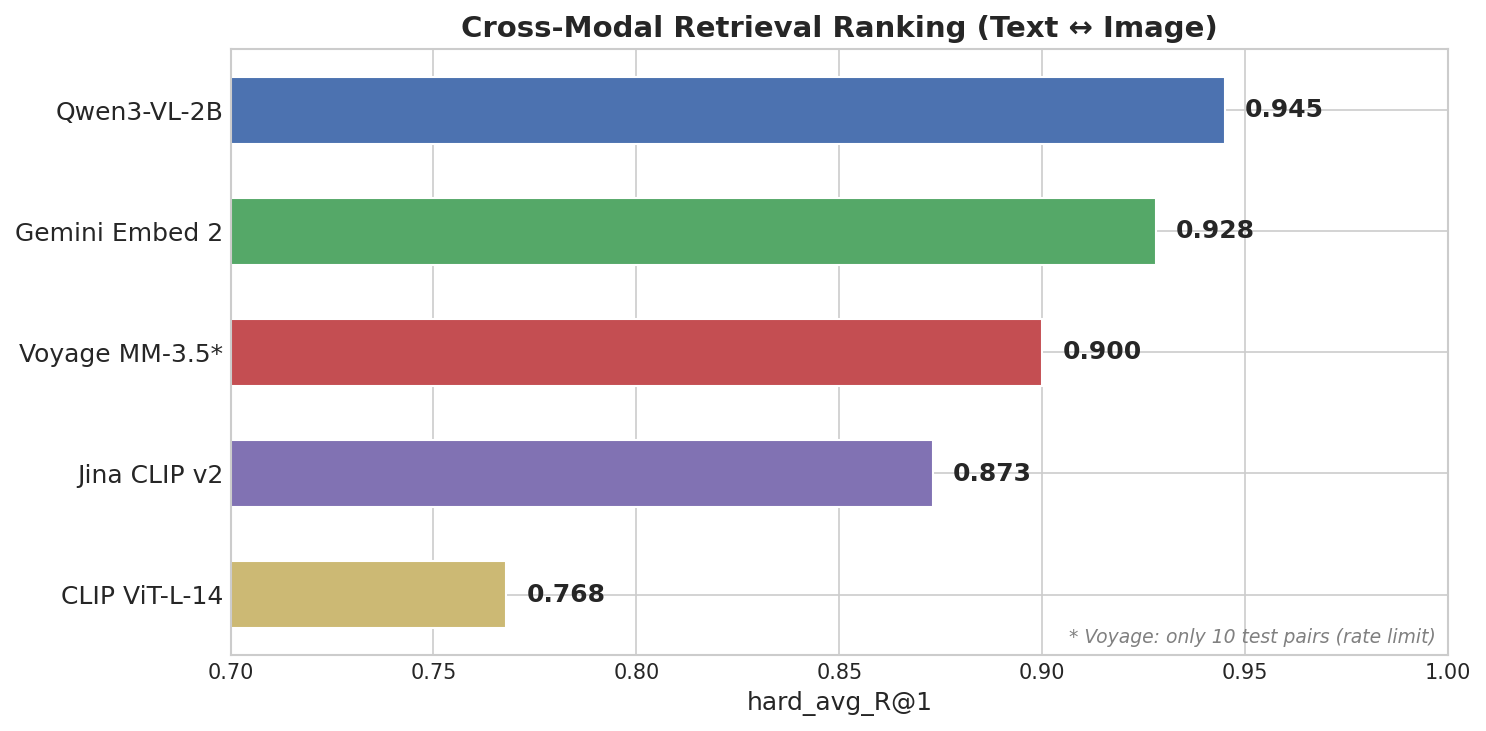
Qwen3-VL-2B took first with hard_avg_R@1 = 0.945, beating Gemini (0.928) and Voyage (0.900). A 2B open-source model outperformed closed-source APIs.
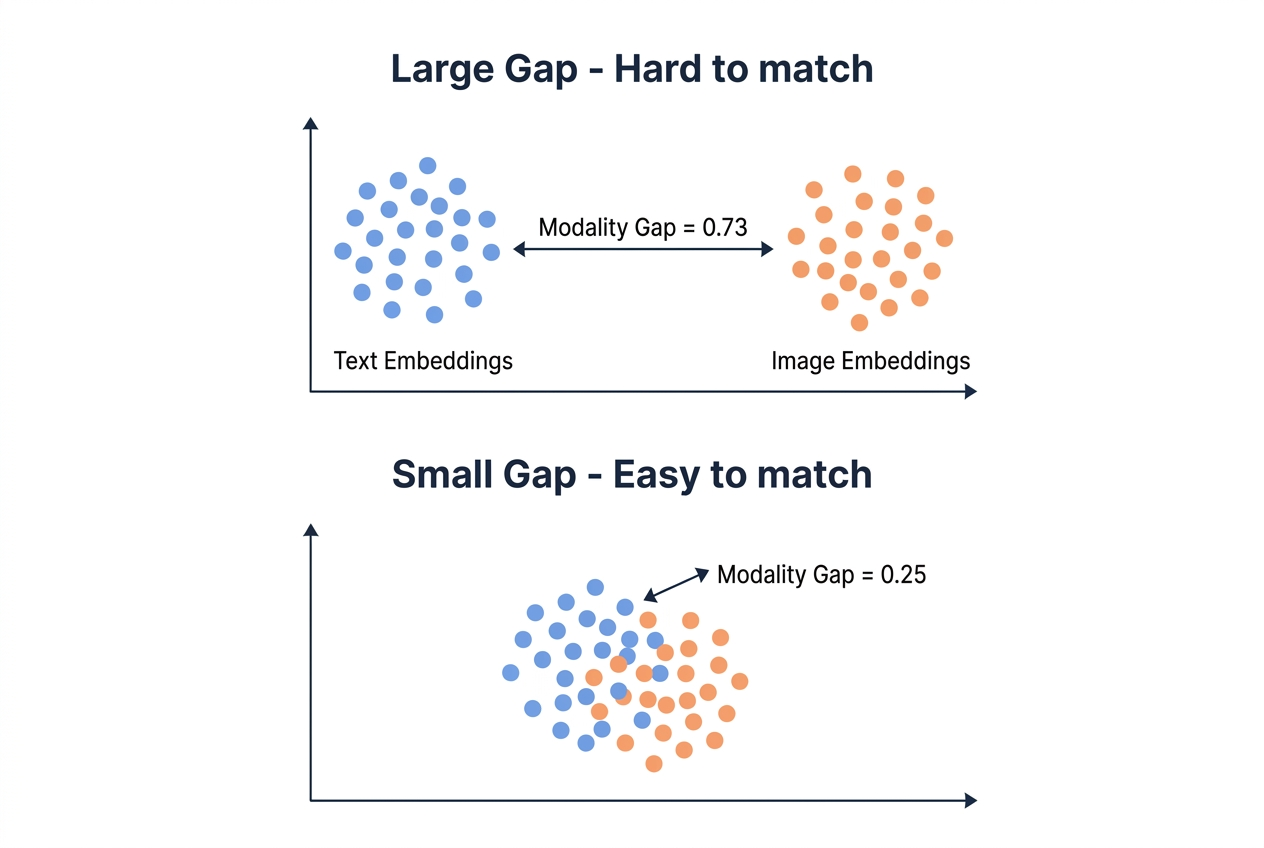
Why? Look at the Modality Gap — the L2 distance between the mean text embedding vector and the mean image embedding vector. A smaller gap means text and image vectors live closer together in the embedding space, making cross-modal retrieval easier.
| Model | hard_avg_R@1 | Modality Gap | Params |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embed 2 | 0.928 | 0.73 | Unknown (closed) |
| Voyage MM-3.5 | 0.900 | 0.59 | Unknown (closed) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
Qwen3-VL-2B’s modality gap of 0.25 is far smaller than Gemini’s 0.73. If you’re building a mixed text-image collection in Milvus, a smaller modality gap means text and image vectors can coexist in the same index without extra alignment tricks.
Takeaway from Round 1: In cross-modal capability, open-source small models can already compete with closed-source APIs.
Round 2: Cross-Lingual Retrieval (Chinese ↔ English)
Scenario: Bilingual knowledge bases where users ask in Chinese but answers live in English documents, or vice versa.
Task design: 166 manually constructed Chinese-English parallel sentence pairs across three difficulty levels, plus 152 hard negative distractors per language.
Difficulty levels:
Level Chinese English Hard Negative Easy 我爱你。 I love you. — Medium 这道菜太咸了。 This dish is too salty. “This dish is too sweet.” / “This soup is too salty.” Hard 画蛇添足 To gild the lily “To add fuel to the fire” / “To let the cat out of the bag” Mapping “画蛇添足” (literally “drawing legs on a snake”) to “To gild the lily” — this kind of cultural concept alignment is the hardest part.
Results
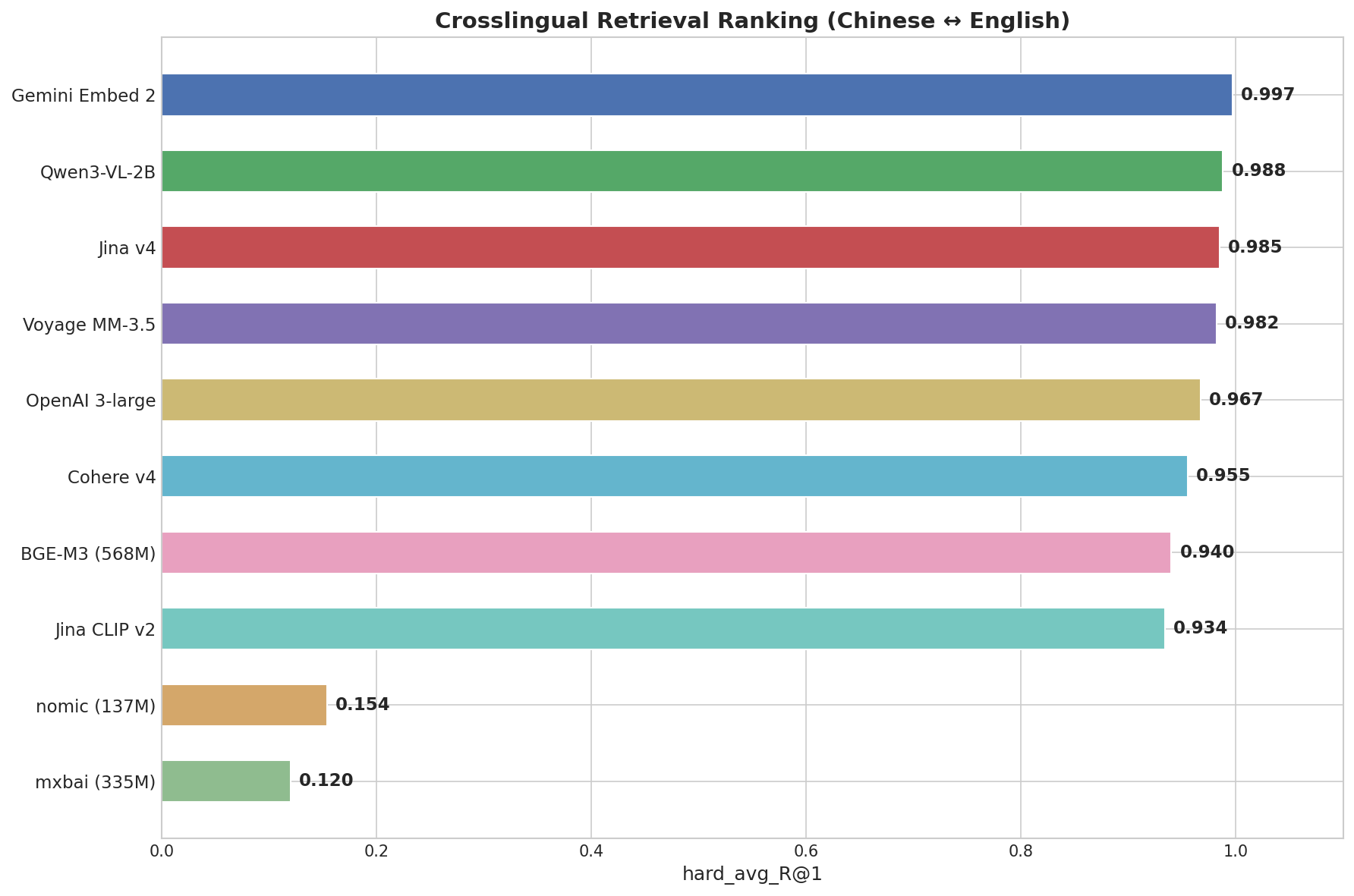
Gemini dominated here with 0.997, near-perfect, nailing even idiomatic expressions. It was the only model with R@1 = 1.000 on the Hard subset.
| Model | hard_avg_R@1 | Easy | Medium | Hard (idioms) |
|---|---|---|---|---|
| Gemini Embed 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage MM-3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
This task split models into two clear groups: the top 8 (R@1 > 0.93) have genuine multilingual capability, while nomic and mxbai (R@1 < 0.16) essentially only understand English. No middle ground.
Round 3: Needle-in-a-Haystack
Scenario: RAG systems processing lengthy legal contracts, research papers. Can the embedding model still find key information buried in tens of thousands of characters?
Task design: Wikipedia articles as the “haystack” (4K-32K characters), with a fabricated fact inserted at different positions (start / 25% / 50% / 75% / end) as the “needle.” The model must correctly rank the needle-containing document higher than the needle-free version via embedding similarity.
Example:
Needle: “The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025.”
Query: “What was Meridian Corporation’s quarterly revenue?”
Haystack: A 32,000-character Wikipedia article about photosynthesis, with the revenue fact hidden somewhere inside.
Results
The discrimination here was bigger than I expected.
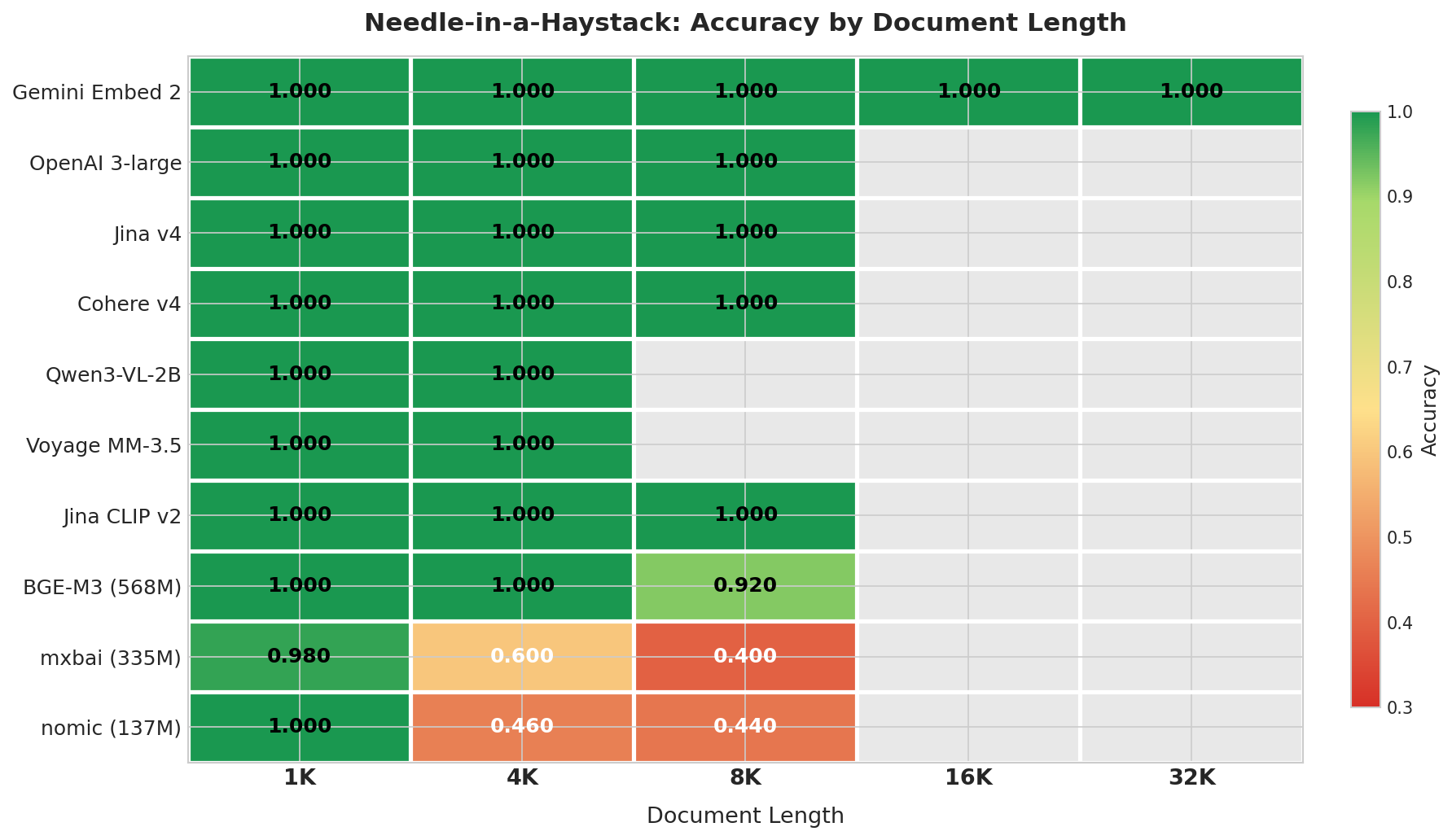
| Model | 1K | 4K | 8K | 16K | 32K | Overall | Degradation |
|---|---|---|---|---|---|---|---|
| Gemini Embed 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage MM-3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
“—” means the length exceeds the model’s context window or wasn’t tested.
Three tiers emerged. Gemini, OpenAI, Jina v4, and Cohere scored near-perfect within their context windows. BGE-M3 (568M) showed slight degradation at 8K (0.92). Models under 335M (mxbai, nomic) dropped significantly at 4K, hitting 0.40-0.44 accuracy at 8K.
Gemini was the only model that completed the full 4K-32K range with a perfect score. On the other end, sub-335M models fell to 0.46-0.60 at just 4K characters (~1000 tokens) — if your RAG documents average over 2000 words, keep this in mind.
Round 4: MRL Dimension Compression
What is MRL?
MRL (Matryoshka Representation Learning) is a training technique that makes the first N dimensions of an embedding vector form a meaningful low-dimensional representation on their own. For example, a 3072-dim vector truncated to its first 256 dimensions can still retain decent semantic quality. Half the dimensions = half the storage cost.

Task design: 150 sentence pairs from STS-B (Semantic Textual Similarity Benchmark), each with human-annotated similarity scores (0-5). Models generate embeddings at full dimensions, then truncated to 256 / 512 / 1024 dims, measuring Spearman rank correlation (ρ) with human scores at each dimension.
Results
If you’re planning to reduce storage costs by truncating embedding dimensions in your vector database, pay attention here.
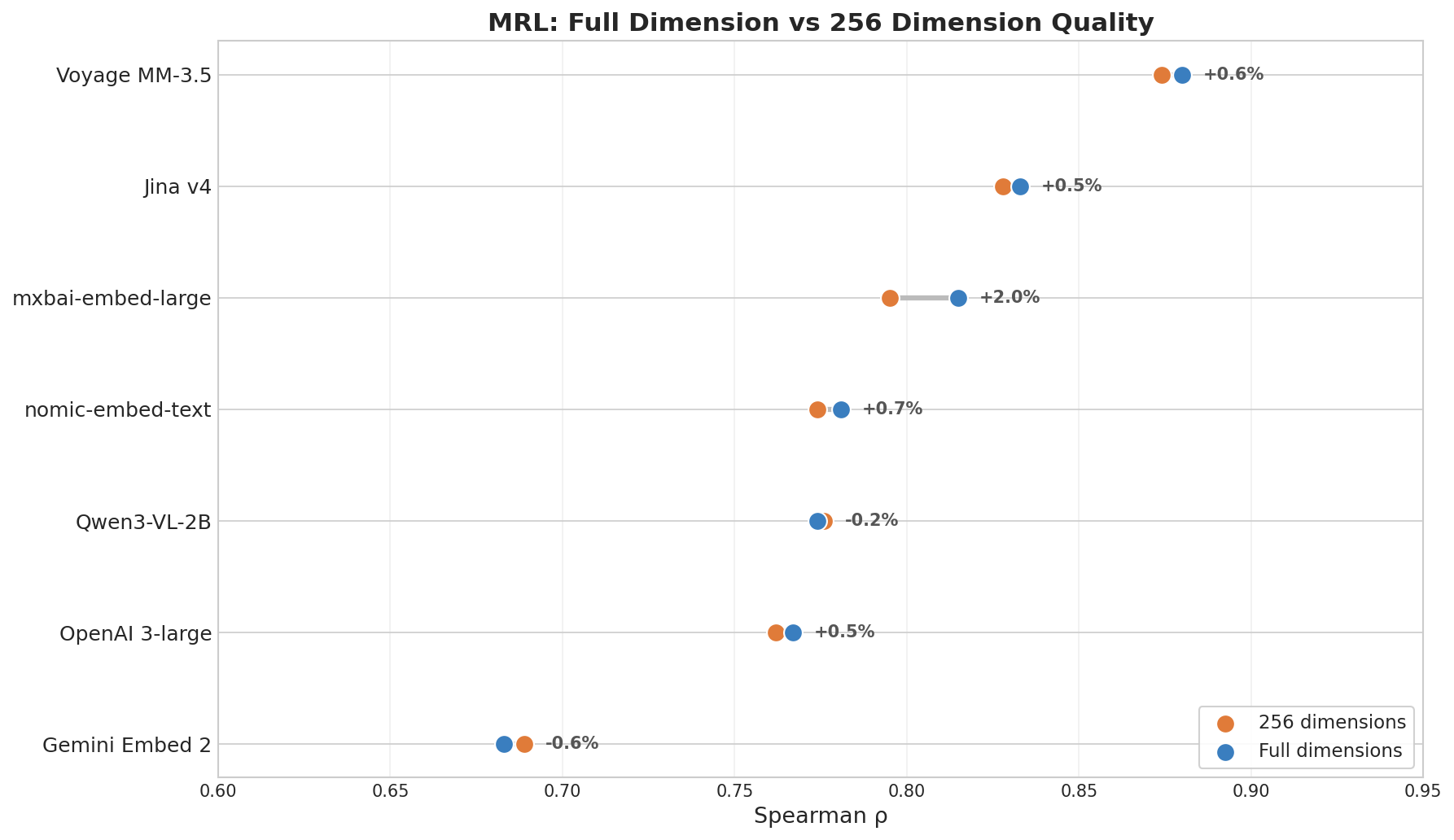
| Model | ρ (Full dim) | ρ (256 dim) | Degradation |
|---|---|---|---|
| Voyage MM-3.5 | 0.880 | 0.874 | 0.7% |
| Jina v4 | 0.833 | 0.828 | 0.6% |
| mxbai (335M) | 0.815 | 0.795 | 2.5% |
| nomic (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embed 2 | 0.683 | 0.689 | -0.8% |
Gemini ranked last in this round. mxbai-embed-large (just 335M params) placed third in MRL, beating OpenAI 3-large. Jina v4 and Voyage led because they were specifically trained with MRL objectives. Dimension compression ability has little to do with model size — what matters is whether it was explicitly trained for it.
Note: MRL rankings reflect dimension-compression resilience, which is different from full-dimension semantic quality. Gemini’s full-dimension retrieval is strong (proven in cross-lingual and cross-modal rounds), but it scored low on this slimming test. If you don’t need dimension compression, this round’s results matter less.
Full Scorecard
| Model | Params | Cross-Modal | Cross-Lingual | Needle | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embed 2 | Unknown | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage MM-3.5 | Unknown | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| OpenAI 3-large | Unknown | — | 0.967 | 1.000 | 0.760 |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| Cohere v4 | Unknown | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
“—” means the model doesn’t support that capability or wasn’t tested. CLIP included as a 2021 baseline.
One thing is clear: no single model wins every round. Gemini leads in cross-lingual and long documents but ranks last in MRL. Qwen3-VL-2B takes first in cross-modal but is mid-pack on MRL. Voyage is consistently strong but never first. Every model’s scorecard has a different shape.
Conclusions and Selection Guide
Round-by-Round Summary
Cross-modal: Qwen3-VL-2B (0.945) took first, Gemini (0.928) second, Voyage (0.900) third. Open-source 2B model beat closed-source APIs — modality gap was the key differentiator.
Cross-lingual: Gemini (0.997) led by a wide margin, handling even idiom-level Chinese-English alignment perfectly. Top 8 models all scored above 0.93; English-only lightweight models essentially scored zero.
Needle-in-a-haystack: API and large open-source models scored perfectly within 8K; sub-335M models degraded starting at 4K. Gemini was the only model to achieve a perfect score across the full 32K range.
MRL compression: Voyage (0.880) and Jina v4 (0.833) led, with less than 1% degradation when truncated to 256 dims. Gemini (0.668) ranked last.
Gemini Embedding 2 Verdict
Back to the question I started with — how did Gemini Embedding 2 actually perform?
Strengths: Cross-lingual #1 (0.997), needle-in-a-haystack #1 (1.000), cross-modal #2 (0.928), broadest modality coverage (five modalities — other models max out at three).
Weaknesses: MRL compression ranked last (ρ=0.668), cross-modal accuracy beaten by open-source Qwen3-VL-2B.
If you don’t need dimension compression, Gemini is currently unmatched for cross-lingual + long-document scenarios. But for cross-modal precision and dimension compression, specialized models do better.
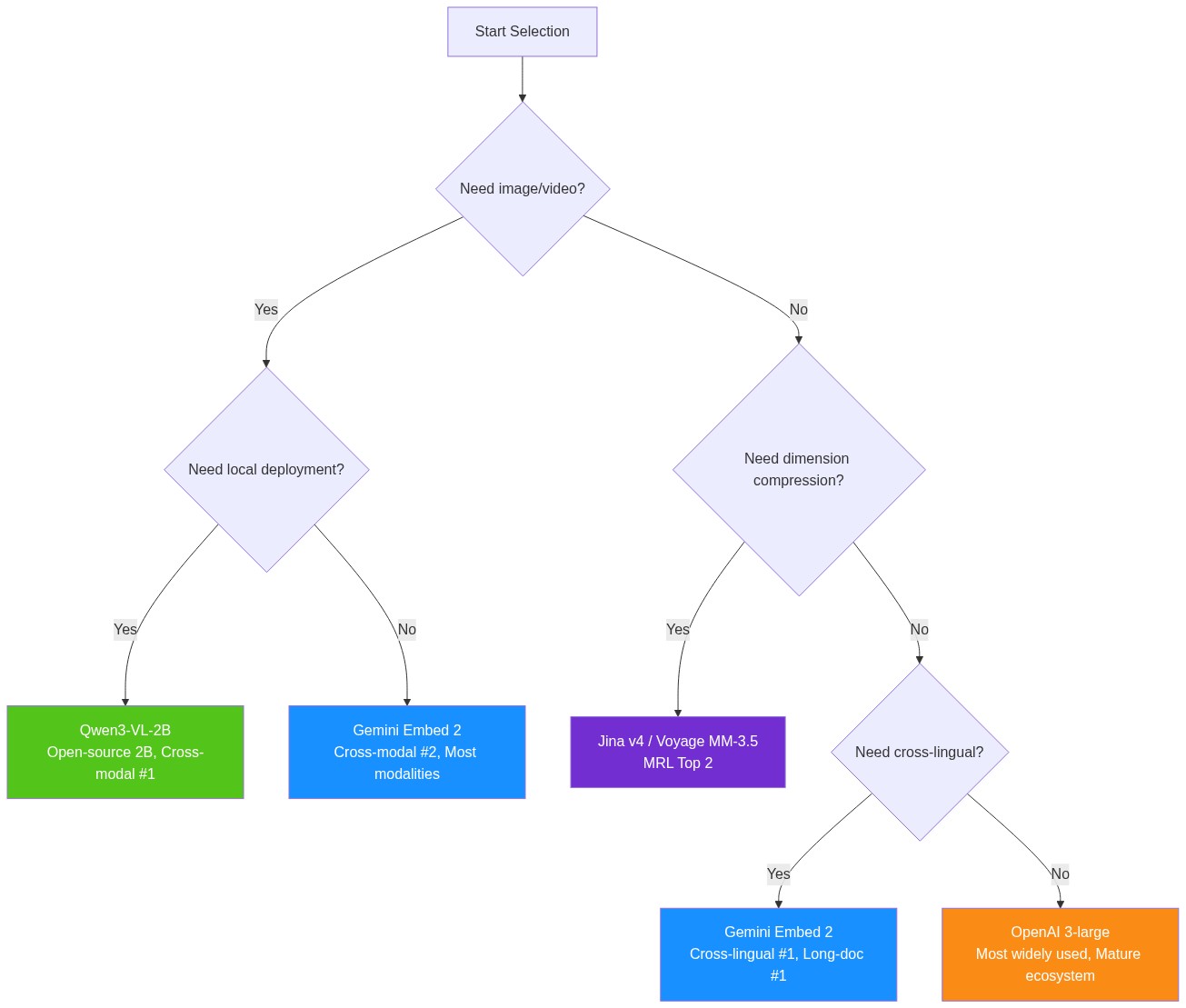
Selection Decision Tree
Based on these benchmark results, here’s a simple decision flow:
Limitations
A few models I didn’t get to test: NVIDIA’s NV-Embed-v2, Jina v5-text. I also didn’t cover video, audio, or PDF/table modalities even though some models claim support, nor did I test domain-specific scenarios like code retrieval. The sample sizes are relatively small — ranking differences between some models may fall within statistical margin of error. More thorough testing is on my to-do list.
Final Thoughts
After running four rounds of benchmarks, a few things stood out to me.
Cross-lingual semantic alignment used to be a research topic in academic papers — now you can get it from an API call. Five years ago, text-image retrieval meant training a dedicated CLIP model; now a single general-purpose model handles text, images, video, audio, and PDFs. This field is moving faster than most people realize.
What impressed me most was how fast open-source is catching up. Qwen3-VL-2B has just 2B parameters yet beat every closed-source API in cross-modal accuracy. BGE-M3’s cross-lingual performance rivals most commercial services. In the embedding space, data quality and training strategy matter more and more, while model size and compute are becoming less decisive. You don’t need to worry about being locked into any single API — there’s always an open-source alternative.
One last thought on model selection. The conclusions in this post will probably need updating in a year. Rather than agonizing over “which model is THE one,” I’d invest in building an evaluation pipeline — understand your actual use case and data, set up a test workflow that can quickly validate new models when they drop. Public benchmarks like MTEB, MMTEB, and MMEB are useful references, but you ultimately need to validate on your own data. The evaluation code for this post is open-sourced on GitHub if you want to adapt it. In the long run, building this evaluation capability is more valuable than picking the right model at any single point in time.