Bilingual Semantic Highlight & Context Pruning Model Release
12 Jan 2026 - Cheney Zhang
Bilingual Semantic Highlight & Context Pruning Model Release
The Token Cost Problem in Production RAG Systems
When deploying RAG systems in production, retrieval quality and LLM performance are often satisfactory initially, but token costs can quickly spiral out of control. A typical query might require feeding 10 documents to the LLM, with each document containing several thousand tokens, resulting in tens of thousands of tokens consumed per query. The fundamental issue is that among these 10 documents, only a few dozen sentences actually contain relevant information, while the rest constitutes noise that distracts the LLM and degrades answer quality.
Manual review of retrieval results to identify truly relevant sentences quickly becomes impractical at scale. This approach fundamentally doesn’t scale and highlights a critical gap in the RAG pipeline: the need for automated semantic-aware sentence-level filtering.
Automated Semantic Highlighting as a Solution
Consider a model that can automatically highlight sentences within retrieved documents that are semantically relevant to the query—not through simple keyword matching, but through genuine semantic understanding. Such a model would enable passing only the highlighted sentences to the LLM, which are the ones that actually address the query.
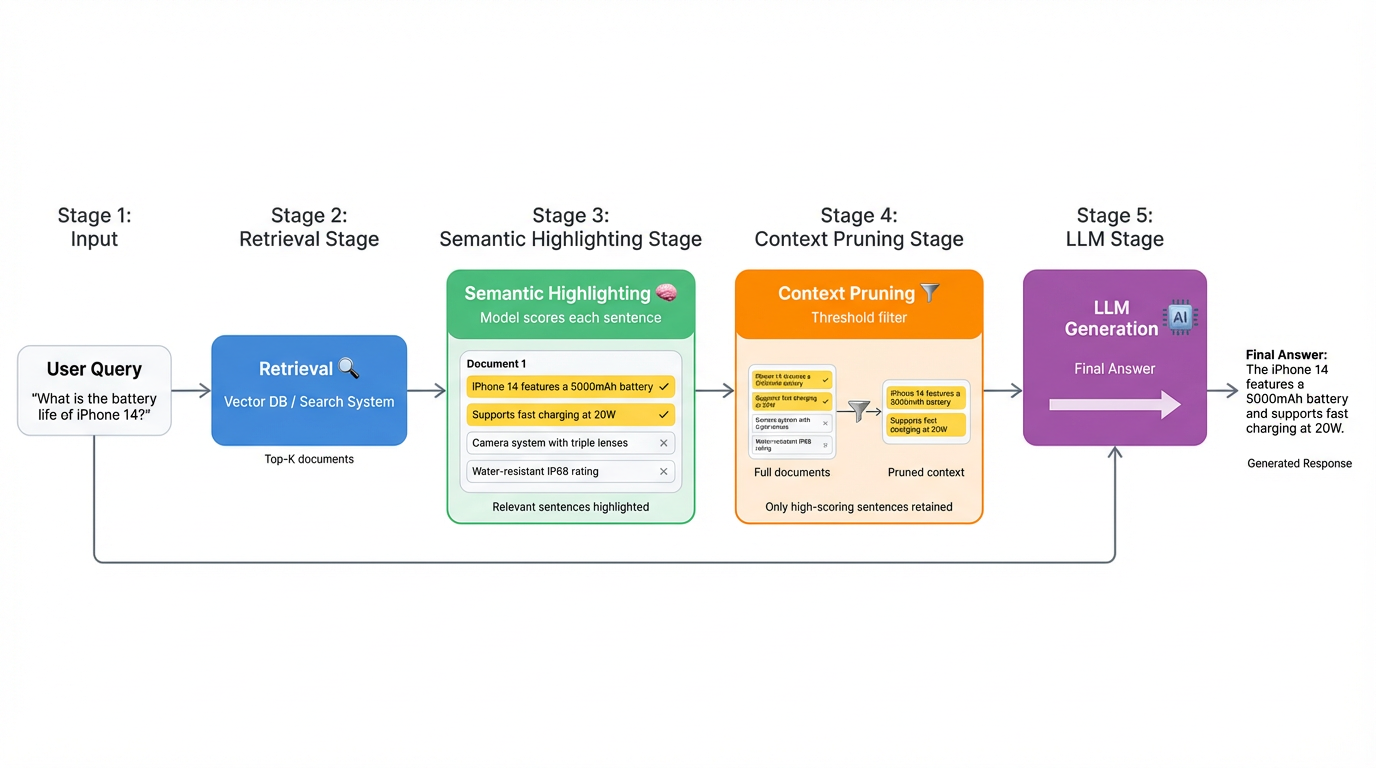
This approach offers several significant advantages. Token costs can be reduced by 70-80% by sending only highlighted sentences to the LLM. Answer quality improves as the LLM focuses on relevant content without noise interference. The system gains interpretability, making it immediately clear why specific documents were retrieved and which sentences are critical. Debugging becomes substantially easier, allowing engineers to trace whether failures stem from retrieval errors, buried relevant sentences, or suboptimal chunking strategies.
While using an LLM for this task might seem straightforward, it creates a paradoxical situation of using expensive models to solve cost problems caused by expensive models. What’s needed is a lightweight, fast, and cost-effective small model specifically designed for this task.
Introducing the Trained Model
Existing models in this space have various limitations: English-only support, small context windows (512 tokens), or restrictive licenses that prohibit commercial use. None simultaneously satisfy the requirements of strong bilingual performance, sufficient context window, good generalization capability, and commercial-friendly licensing.
I trained a model called Semantic Highlight to address these requirements. It performs semantic understanding to highlight relevant sentences and prune irrelevant ones, significantly reducing RAG costs. As a small model with fast inference and low computational requirements, it’s suitable for production deployment and supports both Chinese and English.
The model weights are open-sourced under the MIT license for commercial use.
HuggingFace: zilliz/semantic-highlight-bilingual-v1

Performance: Bilingual State-of-the-Art
The model achieves state-of-the-art performance on both Chinese and English datasets in out-of-domain testing, where test data distributions differ completely from training data distributions.

The model ranks first across all four evaluation datasets. Notably, it’s the only model that demonstrates strong performance on both Chinese and English datasets. Other models either support only English or show significant performance degradation on Chinese text. For example, the XProvence series achieves only 0.45-0.47 on Chinese wikitext2, while this model achieves 0.60.
How It Works
The inference process is straightforward. The input consists of a query and a text passage, and the output is a relevance score for each token position in the text. Token scores are then aggregated into sentence scores, and a threshold is applied to highlight or remove sentences accordingly.
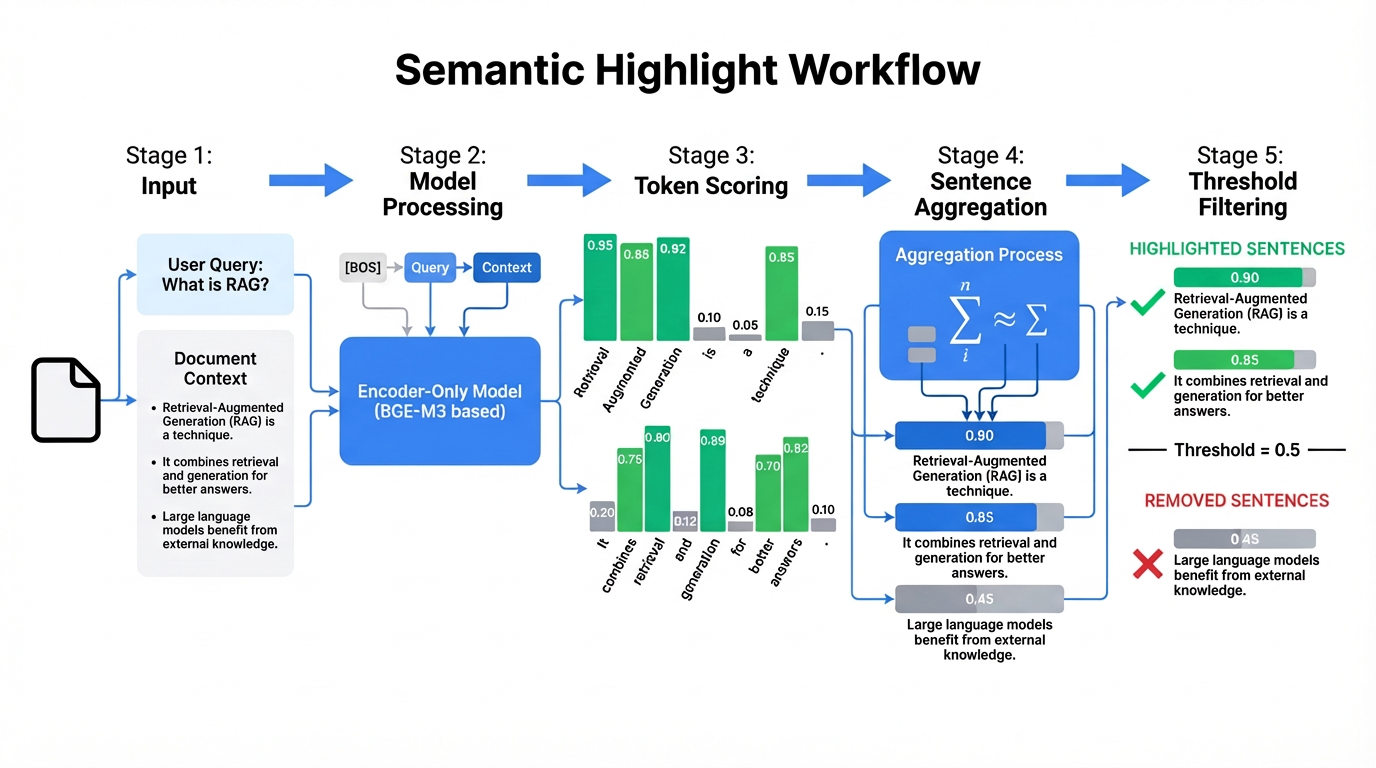
Specifically, the model concatenates inputs as [BOS] + Query + Context, scores each token in the context (between 0 and 1), averages token scores within each sentence to obtain sentence scores, and finally highlights sentences with high scores while removing those with low scores. The model essentially performs a single pass over the context, using scores to indicate which parts merit attention.
Model Architecture: Provence Approach
This approach is based on Provence, a model specifically designed for context pruning, published by Naver at ICLR 2025.

The core concept is using a lightweight Encoder-Only model that frames context pruning as a token-level scoring task.
Encoder-Only: BERT-style Architecture
This architecture, identical to BERT from 8 years ago, is Encoder-Only. Despite its age, it offers significantly faster speed and efficiency compared to modern LLMs. Its key characteristic is the ability to train and infer a score for each token position simultaneously, outputting all token scores in parallel.
This differs fundamentally from popular Decoder-Only LLMs, which generate tokens sequentially. Encoder-Only models process in parallel, scoring all positions at once, resulting in much faster inference. Additionally, Encoder-Only models are typically compact—0.6B parameters suffice for strong performance—making them well-suited for simple NLP tasks like per-token scoring.
Post-processing is straightforward: after obtaining token scores, they’re aggregated into sentence scores to determine relevance, with sentences above the threshold designated as highlights.
Base Model: BGE-M3 Reranker v2
I selected BGE-M3 Reranker v2 as the base model for several reasons. It employs an Encoder architecture suitable for token and sentence scoring, supports multiple languages with optimization for both Chinese and English, provides an 8192-token context window appropriate for longer RAG documents, and maintains 0.6B parameters—strong enough without being computationally heavy while ensuring sufficient world knowledge in the base model. Furthermore, it’s trained for reranking, which closely aligns with relevance judgment tasks, making transfer learning more efficient.
Training Data: Self-Generated with Reasoning Process
With the model architecture selected, the question became where to source training data. I generated the data myself, drawing inspiration from Open Provence’s data construction methodology. Their data comes from public QA datasets, using a small LLM to annotate which sentences are relevant—what they call “silver labels.”
While this approach is sound, I identified an area for improvement. Traditional methods rely either on manual annotation (expensive and slow) or direct LLM outputs (unstable and difficult to tune). My strategy involved having the LLM write out its reasoning process when assigning labels. This means each training sample includes not just Query, Context, and Sentence Spans fields, but also an important Think Process field.
Though this seems verbose, it offers clear benefits. Annotation accuracy improves as writing the reasoning process serves as self-verification, reducing errors. It provides observability—I can see why specific sentences were selected. It enables debugging by revealing whether incorrect annotations stem from prompt issues or knowledge gaps. It’s reusable, providing reference explanation patterns for future re-annotation with different models.

I used Qwen3 8B for annotation, as it naturally supports a thinking mode with <think> outputs. The 8B size strikes the right balance—smaller models lack stability, while larger ones are too slow and expensive. Annotation used a local vLLM service rather than cloud APIs, providing high concurrent throughput and cost efficiency by trading GPU time for token costs.
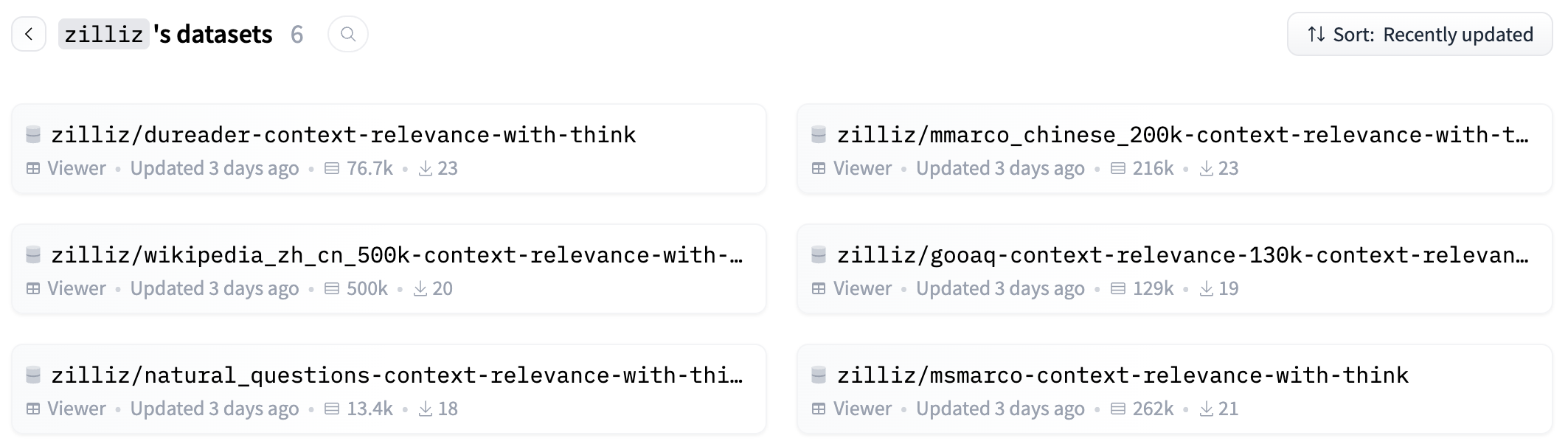
Ultimately, I constructed over 5 million bilingual training samples, split evenly between Chinese and English. English data came from MS MARCO, Natural Questions, and GooAQ, while Chinese data came from DuReader, Chinese Wikipedia, and mmarco_chinese. Some data originated from Open Provence and similar sources with re-annotation, while other portions were generated from raw corpora with query and context generation followed by annotation.
All annotated training data is also open-sourced on HuggingFace for community development and training reference.
With the model architecture and dataset prepared, training proceeded on 8 A100 GPUs for 3 epochs over approximately 9 hours, resulting in the model uploaded to HuggingFace: zilliz/semantic-highlight-bilingual-v1.
Standing on the Shoulders of Giants
This model’s development builds on significant prior work. I referenced Provence’s theoretical foundation, which proposed an elegant approach of using lightweight Encoder models for context pruning. I utilized the Open Provence codebase (open-source licensed), which provided well-implemented training pipelines, data processing, and model heads, eliminating the need to reinvent these components.
Building on these foundations, I contributed several innovations: LLM annotation with reasoning processes to improve data quality, over 5 million bilingual training samples covering Chinese and English scenarios aligned with practical needs, selection of a base model more suitable for RAG scenarios (BGE-M3 Reranker v2), and focused training on the Pruning Head for the Semantic Highlight task without training the Rerank Head.
I extend sincere thanks to the Provence team and Open Provence project contributors for their foundational work.
Getting Started
The model is open-sourced under the MIT license and can be confidently used in commercial projects.
HuggingFace: zilliz/semantic-highlight-bilingual-v1
Related Links
- Model Download: zilliz/semantic-highlight-bilingual-v1
- Open Provence Project: hotchpotch/open_provence
- Provence Paper: arXiv:2501.16214
- Provence Official Introduction: Provence: efficient and robust context pruning for retrieval-augmented generation
- Milvus: milvus.io
- Zilliz Cloud: zilliz.com