What is a Semantic Highlight Model?
06 Jan 2025 - Cheney Zhang
What is Traditional Highlighting?
Let me start with a familiar scenario.
When you search for “raincoat” on an e-commerce platform, the word “raincoat” in the returned product titles will be highlighted to indicate the matched query term.
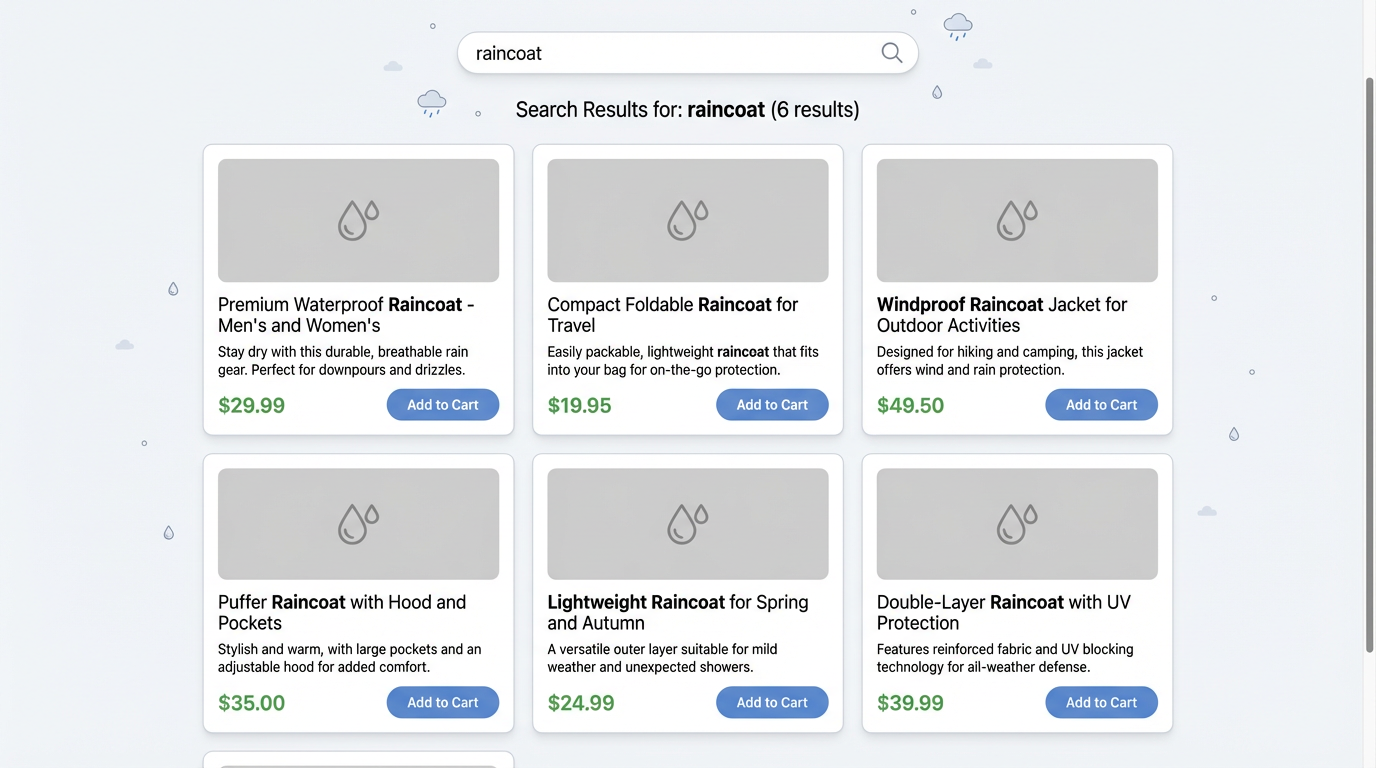
This is traditional search highlighting.
The technology behind it is simple: databases (like Elasticsearch) find where the query terms appear when returning results, wrap them with special tags (usually <em> tags), and the frontend parses and renders them in a highlighted color.
The core logic of this highlighting is keyword matching. Whatever you search for, the system highlights exactly that. It’s like a student using a highlighter pen—wherever the keyword appears gets highlighted.
Simple, but also quite mechanical.
Limitations of Traditional Highlighting
The problems with traditional highlighting manifest differently across various scenarios. Let me examine this from three levels:
Scenario 1: E-commerce Search
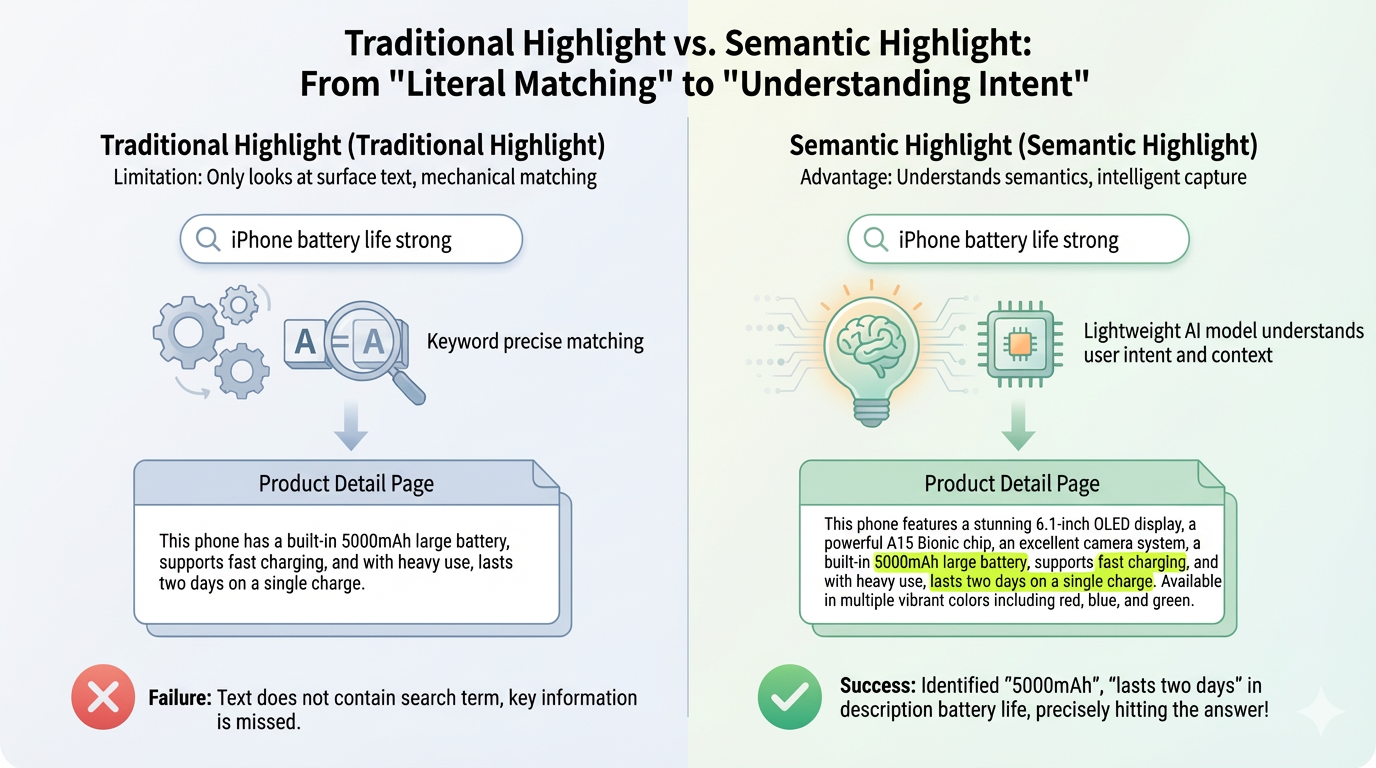
When a user searches “How is iPhone performance?”, the system can only highlight the words “iPhone” and “performance.”
But if the product details say: “Powered by A15 Bionic chip, benchmark scores exceeding 1 million, smooth daily use with no lag”—this clearly answers the performance question, yet because the word “performance” doesn’t appear, nothing gets highlighted.
Users have to read the entire text themselves to determine if this is the information they want.
Scenario 2: RAG Retrieval
The problem becomes more pronounced.
When a user asks: “How to improve Python code execution efficiency?”, the system retrieves a technical document from the vector database.
Traditional highlighting can only mark words like “Python,” “code,” “execution,” and “efficiency.”
But the truly useful content might be: “Use numpy vectorized operations instead of loops” or “Avoid repeatedly creating objects inside loops.”
These sentences semantically answer the question completely, but contain none of the query terms, so traditional highlighting marks nothing.
Users looking at the long retrieved document have to read sentence by sentence to find the answer. Poor experience.
Scenario 3: AI Agents
The problem becomes even more challenging.
Agent search queries are often not the user’s original question, but complex instructions after reasoning and decomposition.
For example, when a user asks “Help me analyze recent market trends,” the Agent might generate a query like: “Retrieve Q4 2024 consumer electronics industry sales data, year-over-year growth rates, major competitor market share changes, and supply chain cost fluctuations.”
Such long queries contain multiple dimensions of information needs with intricate semantic relationships.
Traditional highlighting can only mechanically mark literally matching words like “2024,” “sales data,” and “growth rates.”
But truly valuable analytical conclusions—”iPhone 15 series drove overall market recovery” or “chip supply shortages led to a 15% cost increase”—might not match any keywords.
Agents need to quickly locate truly useful information from massive retrieval results; traditional highlighting simply cannot handle this.
In summary: The core problem of traditional highlighting is focusing on literal matches, not semantic meaning. From simple e-commerce searches to RAG retrieval to AI Agents’ complex queries, this problem becomes increasingly severe.
Semantic Highlight: Understanding Meaning
Semantic Highlight is designed to solve this problem.
It no longer mechanically matches keywords but understands semantics. When a user asks “How is iPhone performance?”, even if the text doesn’t contain the word “performance,” as long as it semantically answers the question (like mentioning chips, benchmarks, or smoothness), it will be highlighted.
In the AI era, this need is relatively easy to implement, but cost and efficiency must be considered.
This requires a lightweight AI model. Why lightweight? Because highlighting is a high-frequency operation—every search requires annotation. Calling large models would mean high latency and costs, making it completely impractical.
So I need a small and fast model—typically a few hundred MB in size, with millisecond-level inference speed, deployable on search servers for real-time computation.
Now the question: Are there ready-made Semantic Highlight models available?
The Dilemma of Existing Models
The answer is yes, but each has its own problems.
OpenSearch’s Model: Small Window, Poor Generalization
OpenSearch released a model specifically for semantic highlighting this year: opensearch-semantic-highlighter-v1.
But it has two fatal issues.
The first is its small context window. This model is based on BERT architecture and can only handle a maximum of 512 tokens. That translates to about 300-400 Chinese characters or 400-500 English words.
In real scenarios, a product details page or technical document often exceeds a thousand words.
The model can only see a small portion at the beginning; the rest is truncated.
It’s like asking someone to judge the key points of an entire article after reading only the first two paragraphs—completely unrealistic.
The second is poor out-of-domain generalization.
What is out-of-domain? Simply put, it’s data types the model hasn’t seen during training.
For instance, if a model is trained on news data and then used to annotate e-commerce reviews, performance drops significantly.
In my previous article’s experiments, I found the OpenSearch model achieved an F1 of 0.72 on in-domain data but dropped to 0.46 on out-of-domain data.
This instability is dangerous in practical applications.
More critically, it doesn’t support Chinese.
Provence/XProvence: Mediocre Performance, License Restrictions
Naver’s Provence series is another option. It’s a model specifically trained for Context Pruning, whose principles I discussed in my previous article.

Although it handles Context Pruning tasks, Context Pruning and Semantic Highlight follow identical technical approaches—both are based on semantic matching to find the most relevant parts and exclude irrelevant ones. Therefore, the Provence series can also be used for Semantic Highlight tasks.
Provence itself is an English model with decent performance. XProvence is its multilingual version, supporting over a dozen languages including Chinese, Japanese, and Korean. To meet my bilingual needs, XProvence might seem like a consideration.
But there are several issues:
First, XProvence underperforms Provence on English.
Multilingual models struggle to excel in all languages.
From evaluation data, XProvence performs slightly weaker than Provence on English datasets. For me, English scenarios are equally important.
Second, Chinese might be an “add-on”.
XProvence supports over a dozen languages, with Chinese being just one.
In multilingual training, the data amount for each language isn’t particularly large. It’s like a pot of porridge—the more ingredients you add, the less taste each has.
Third, there are subtle differences between Pruning and Highlighting tasks.
The Provence series was trained for Context Pruning. The pruning strategy is “better to keep more than miss anything,” because if key information is missed, the LLM can’t answer.
But Semantic Highlight emphasizes precision. I want to highlight the core sentences, not mark half the article in yellow.
Fourth, licensing issues. Provence and XProvence use the CC BY-NC 4.0 license, which prohibits commercial use.
Open Provence: Lacks Chinese Support
I discovered a treasure project: Open Provence

This project fully reproduces Provence’s training code. It includes not only training scripts but also data processing and evaluation tools, and even provides pre-trained models of different scales.
More importantly, it’s completely open source with an MIT license, safe for commercial projects.
But the problem: Open Provence only supports English and Japanese, no Chinese.
My Choice: Train a Bilingual Model Myself
Overall, no existing model can simultaneously meet these requirements:
- Strong in both Chinese and English
- Large enough context window
- Good out-of-domain generalization
- Good performance in Semantic Highlight scenarios
- Friendly license (MIT or Apache 2.0)
Since no suitable model exists on the market, I’ll train one myself.
My Training Approach
Training a model in this scenario isn’t difficult; what’s difficult is training a good model that overcomes all the above problems, meets my needs, and achieves near-SOTA performance.
My core approach: Use LLM to annotate high-quality datasets, train rapidly based on open-source frameworks.
The key is data construction. I have the LLM (Qwen3 8B) output its complete reasoning process during annotation. The annotation workflow roughly follows:
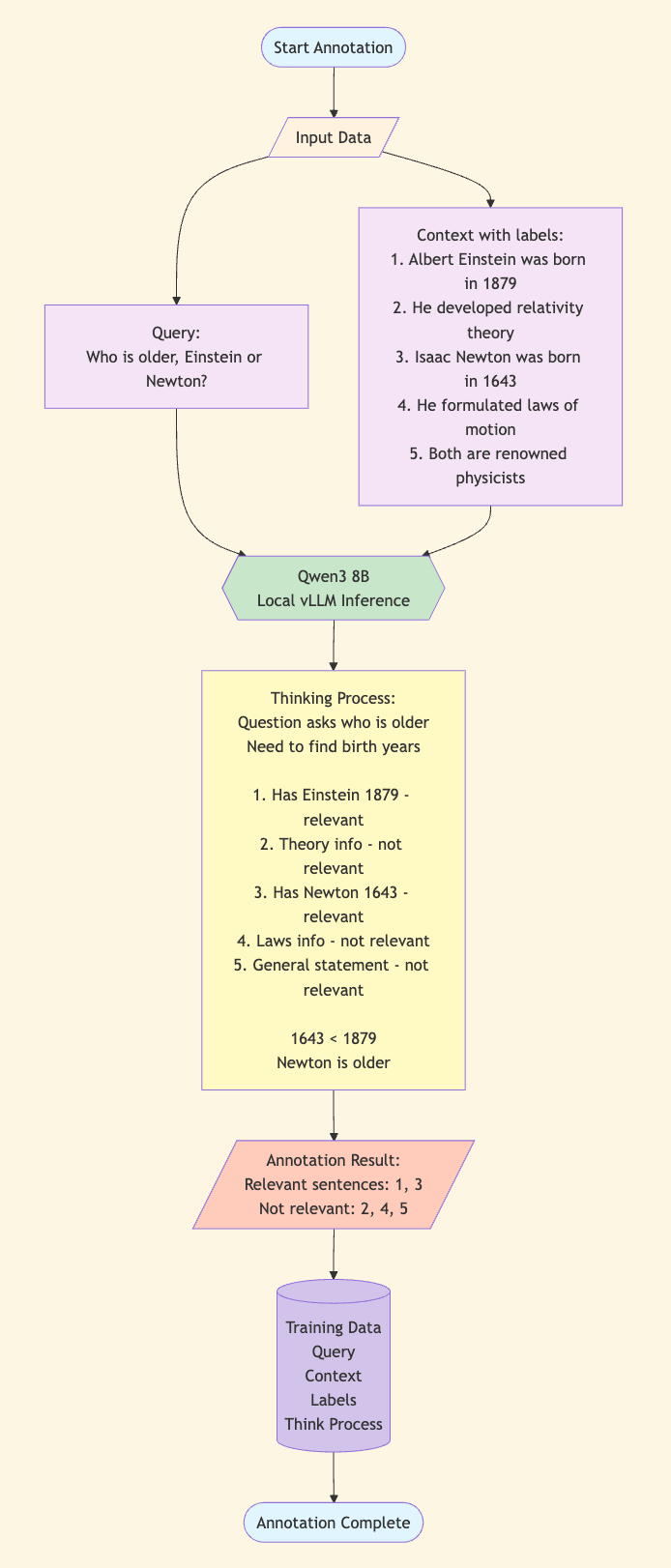
This approach has three benefits:
- Higher annotation quality: The model thinks before answering, essentially self-checking
- Observable and debuggable: I can see the reasoning process and adjust when problems are found
- Data reusability: With the reasoning process, I have references for future re-annotation
Ultimately, I constructed 1M+ (million-scale) bilingual training samples, split evenly between Chinese and English.
Based on BGE-M3 Reranker v2 (0.6B parameters, 8192 token window) as the base model, using Open Provence’s training framework, I trained for 3 epochs on 8 A100 GPUs, completing in about 5 hours.
More technical details about training (why use reasoning mode, how to select the base model, dataset construction process, etc.) will be elaborated in my next article.
Evaluation Results: Achieving SOTA Performance
I compared different models’ performance across multiple datasets, including:
- English multi-span QA dataset (multispanqa)
- Wikipedia out-of-domain dataset (wikitext2)
- Chinese multi-span QA dataset (multispanqa_zh)
- Chinese version of Wikipedia out-of-domain dataset (wikitext2_zh)
Evaluated models include the Open Provence series, Naver’s Provence/XProvence series, OpenSearch’s semantic-highlighter, and my trained bilingual model.
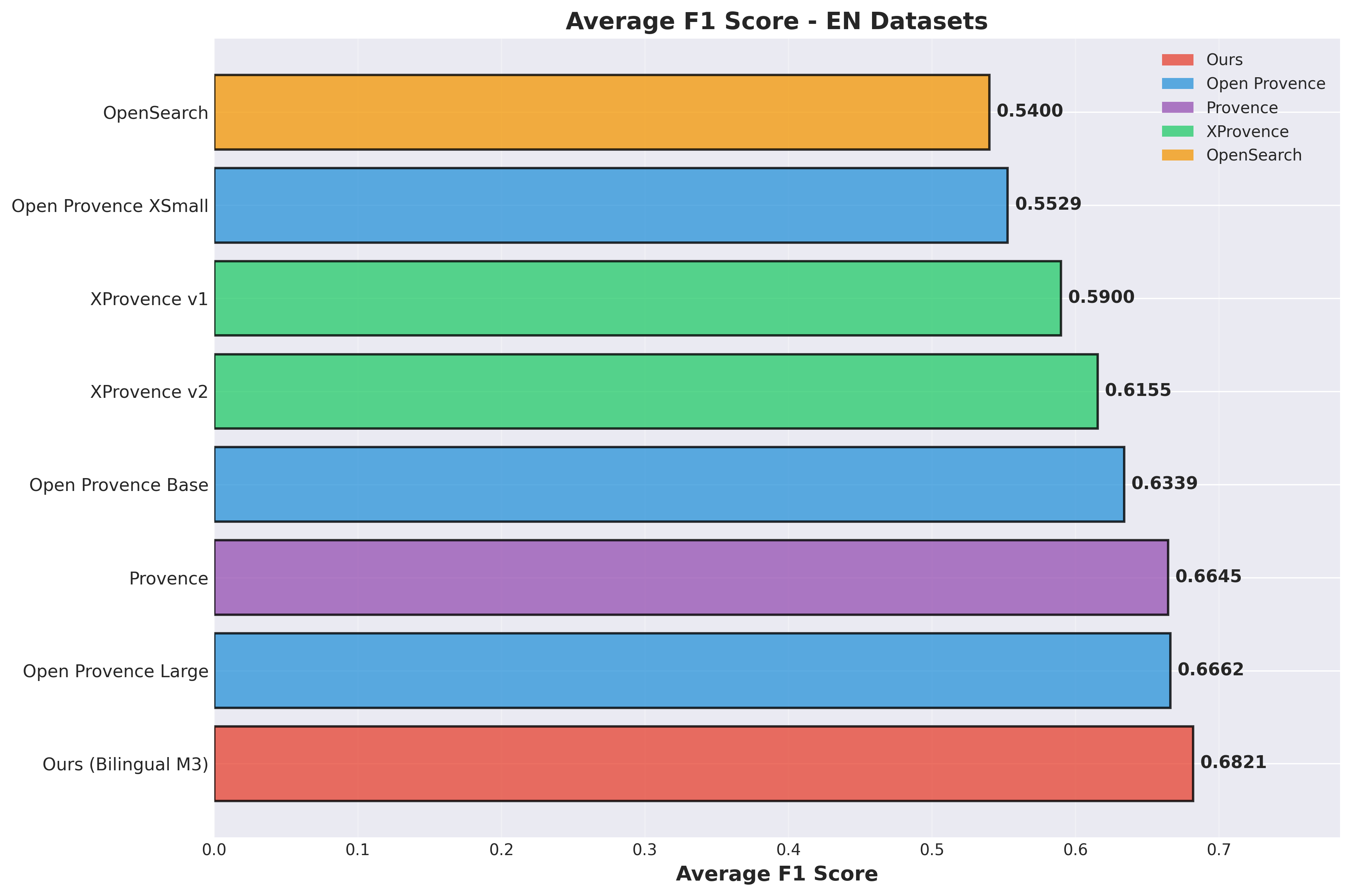
English Datasets
Chinese Datasets
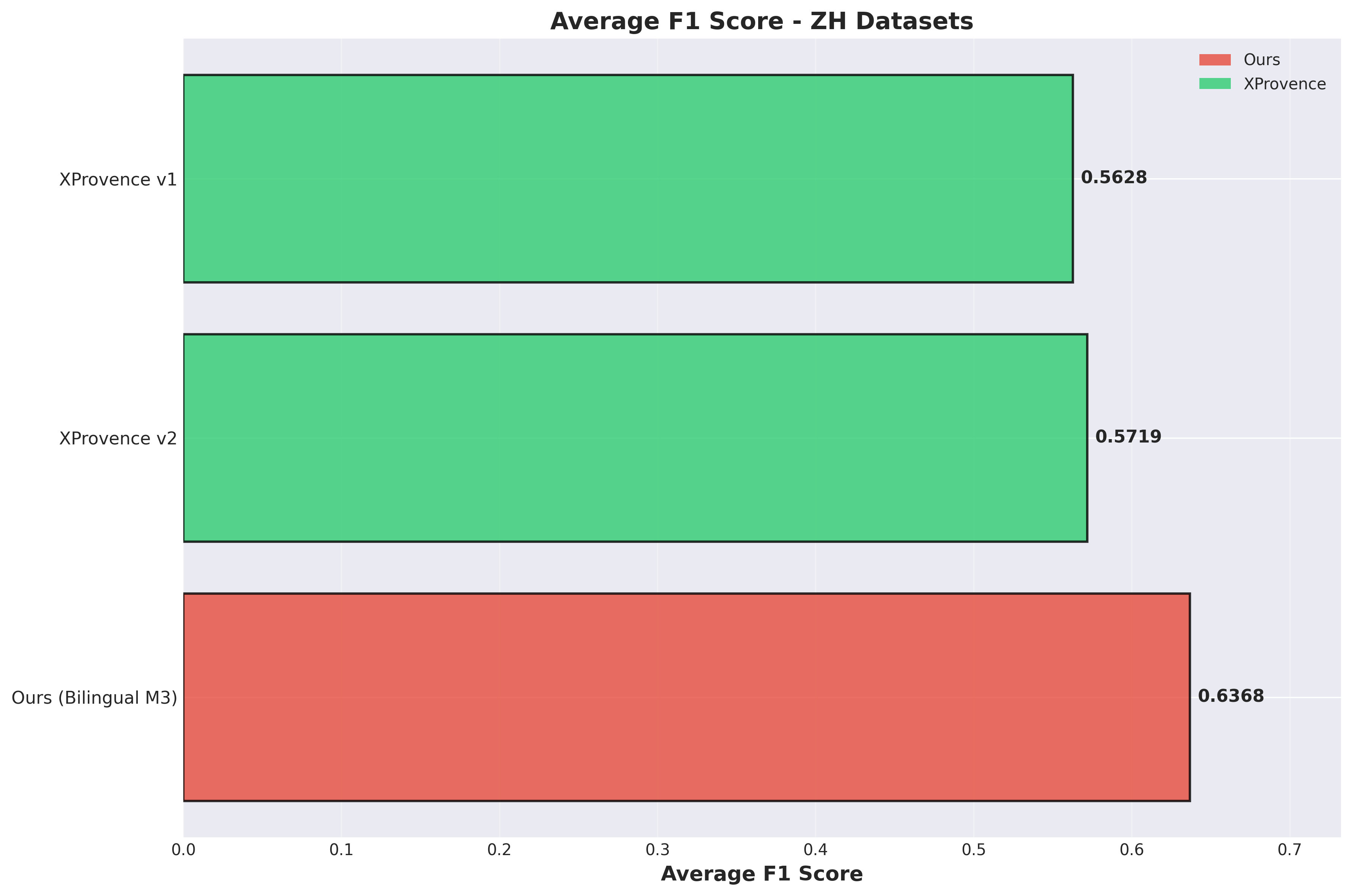
As you can see, in bilingual evaluation, my model’s average F1 achieved SOTA performance, surpassing all previous models and solutions, and significantly outperforming the XProvence series models on Chinese test evaluations.
More importantly, my model achieves balance between Chinese and English, which other models struggle to do:
- Open Provence only supports English
- XProvence underperforms Provence on English
- OpenSearch doesn’t support Chinese and has poor generalization
Real-World Case: Precisely Identifying Core Sentences
Beyond benchmark scores, let me show a more interesting example to intuitively demonstrate my model’s performance in practical applications.
Question: “Who wrote The Killing of a Sacred Deer”
Text (5 sentences total):
1. The Killing of a Sacred Deer is a 2017 psychological horror film directed by Yorgos Lanthimos,
with a screenplay by Lanthimos and Efthymis Filippou.
2. The film stars Colin Farrell, Nicole Kidman, Barry Keoghan, Raffey Cassidy,
Sunny Suljic, Alicia Silverstone, and Bill Camp.
3. The story is based on the ancient Greek playwright Euripides' play Iphigenia in Aulis.
4. The film tells the story of a cardiac surgeon (Farrell) who secretly
befriends a teenager (Keoghan) connected to his past.
5. He introduces the boy to his family, who then mysteriously fall ill.
Correct Answer: Sentence 1 (explicitly states “screenplay by Lanthimos and Efthymis Filippou”)
This example has a trap: Sentence 3 mentions “Euripides” wrote the original play. But the question asks “who wrote the film The Killing of a Sacred Deer,” and the answer should be the film’s screenwriters, not the Greek playwright from thousands of years ago.
Model Performance:
| Model | Found Correct Answer | Prediction |
|---|---|---|
| My Model | ✓ | Selected sentences 1 (correct) and 3 |
| XProvence v1 | ✗ | Only selected sentence 3, missed correct answer |
| XProvence v2 | ✗ | Only selected sentence 3, missed correct answer |
Key Sentence Score Comparison:
| Sentence | My Model | XProvence v1 | XProvence v2 |
|---|---|---|---|
| Sentence 1 (film screenplay, correct answer) | 0.915 | 0.133 | 0.081 |
| Sentence 3 (original play, distractor) | 0.719 | 0.947 | 0.802 |
This result is very interesting:
XProvence’s Problem:
- Strongly attracted by “Euripides” and “play,” giving sentence 3 near-perfect scores (0.947 and 0.802)
- Completely ignores the real answer (sentence 1), giving extremely low scores (0.133 and 0.081)
- Even lowering the threshold from 0.5 to 0.2, it still can’t find the correct answer
My Model’s Performance:
- Gives the correct answer (sentence 1) a high score of 0.915, clearly identifying “film screenwriters”
- Also gives sentence 3 some score (0.719), because it does mention information related to “play”
- But the distinction is very clear: 0.915 vs 0.719, a gap approaching 0.2
This example demonstrates my model’s core advantage: understanding the true intent of questions, not simple keyword matching.
The question “Who wrote The Killing of a Sacred Deer,” in the context of a film encyclopedia, clearly asks about the film’s screenwriters. Although the text contains both “film screenwriters” and “original play” information, my model accurately understands which one the user actually wants.
More detailed evaluation reports and case analyses will be published subsequently.
Conclusion
I’ve now open-sourced the preview version weights of my model on Hugging Face, allowing everyone to start using it early. The address is:
https://huggingface.co/zilliz/semantic-highlight-bilingual-pre
Feel free to try it out and provide feedback anytime.
Additionally, I’m working on turning the model inference into a service, integrating and deploying it to Milvus as a Semantic Highlight interface. This will be available soon.
Imagine this scenario:
You ask a technical question in a RAG system, and Milvus retrieves 5 documents, each several hundred words long. Now you don’t have to read each one—the system directly highlights the most relevant sentences, and you can see where the answer is at a glance.
This not only improves user experience but also makes it easier for developers to debug and optimize, directly seeing retrieval quality and which sentences are truly useful.
I believe Semantic Highlight will become a standard feature in next-generation search and RAG systems.
Related Links:
- Open Provence Project: https://github.com/hotchpotch/open_provence
- Provence Paper: https://arxiv.org/abs/2501.16214
- XProvence Model: https://huggingface.co/naver/xprovence-reranker-bgem3-v1
- OpenSearch Semantic Highlighter: https://huggingface.co/opensearch-project/opensearch-semantic-highlighter-v1
- Milvus: https://milvus.io