Context Engineering and Pruning: Managing Long Context Windows in the Era of Million-Token LLMs
01 Dec 2025 - Cheney Zhang
Context Engineering and Pruning: Managing Long Context Windows in the Era of Million-Token LLMs
The context window length of LLMs is experiencing explosive growth. Looking at the LLM Leaderboard, we can see that top-tier models have successively broken through the 1M token barrier for context length. And this number continues to be refreshed.
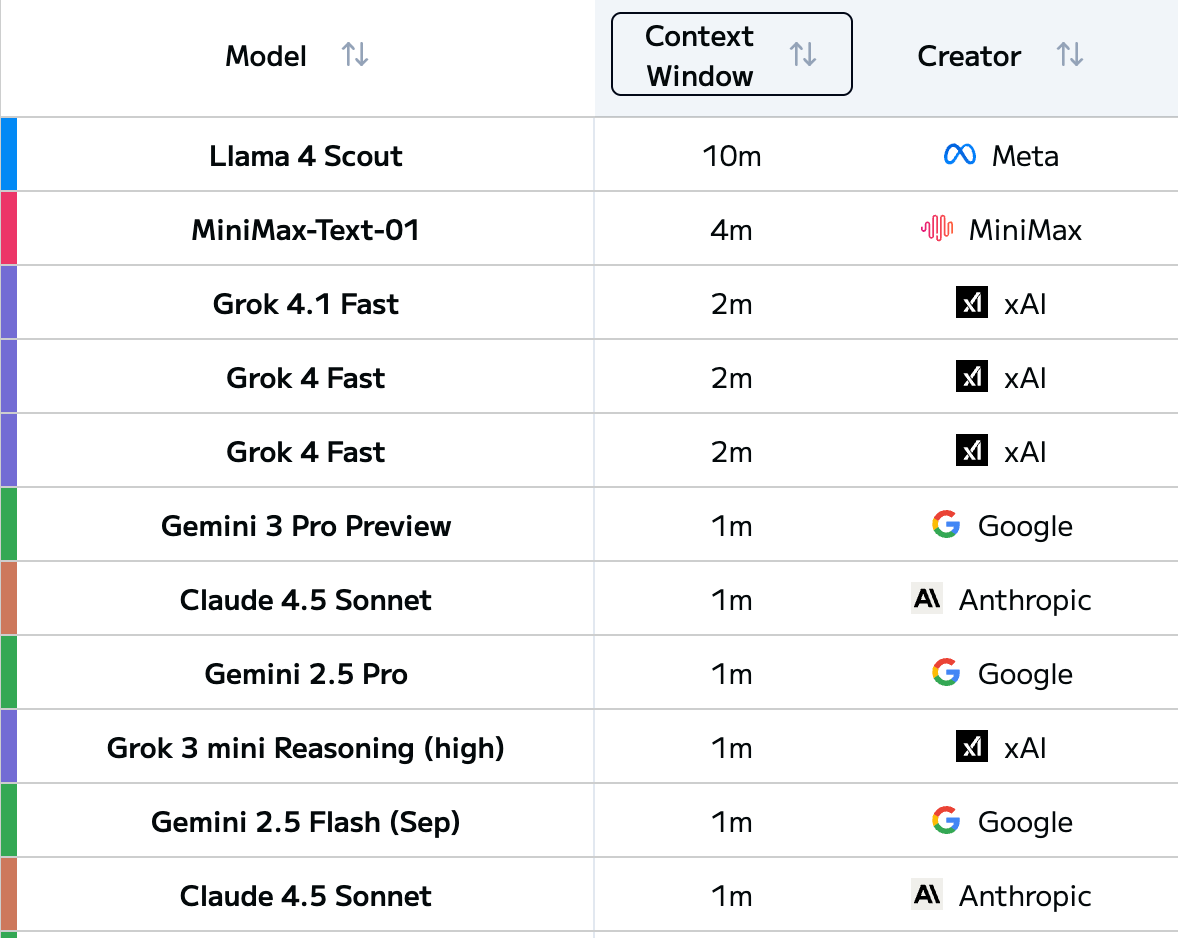
But problems arise accordingly: just because models can support long contexts, does that mean we can freely stuff content into them? Does more input always lead to better model output?
The answer is obviously no.
After all, stuffing a million tokens into a model might not only make most of the information useless, but this content not only wastes computational resources, it can also interfere with the model’s judgment, leading to degraded generation quality.
How to precisely manage and optimize these massive contexts has become the core problem that Context Engineering needs to solve.
So when do long contexts fail? What solutions do we have for model output collapse caused by long contexts?
01 Four Failure Modes of Long Context
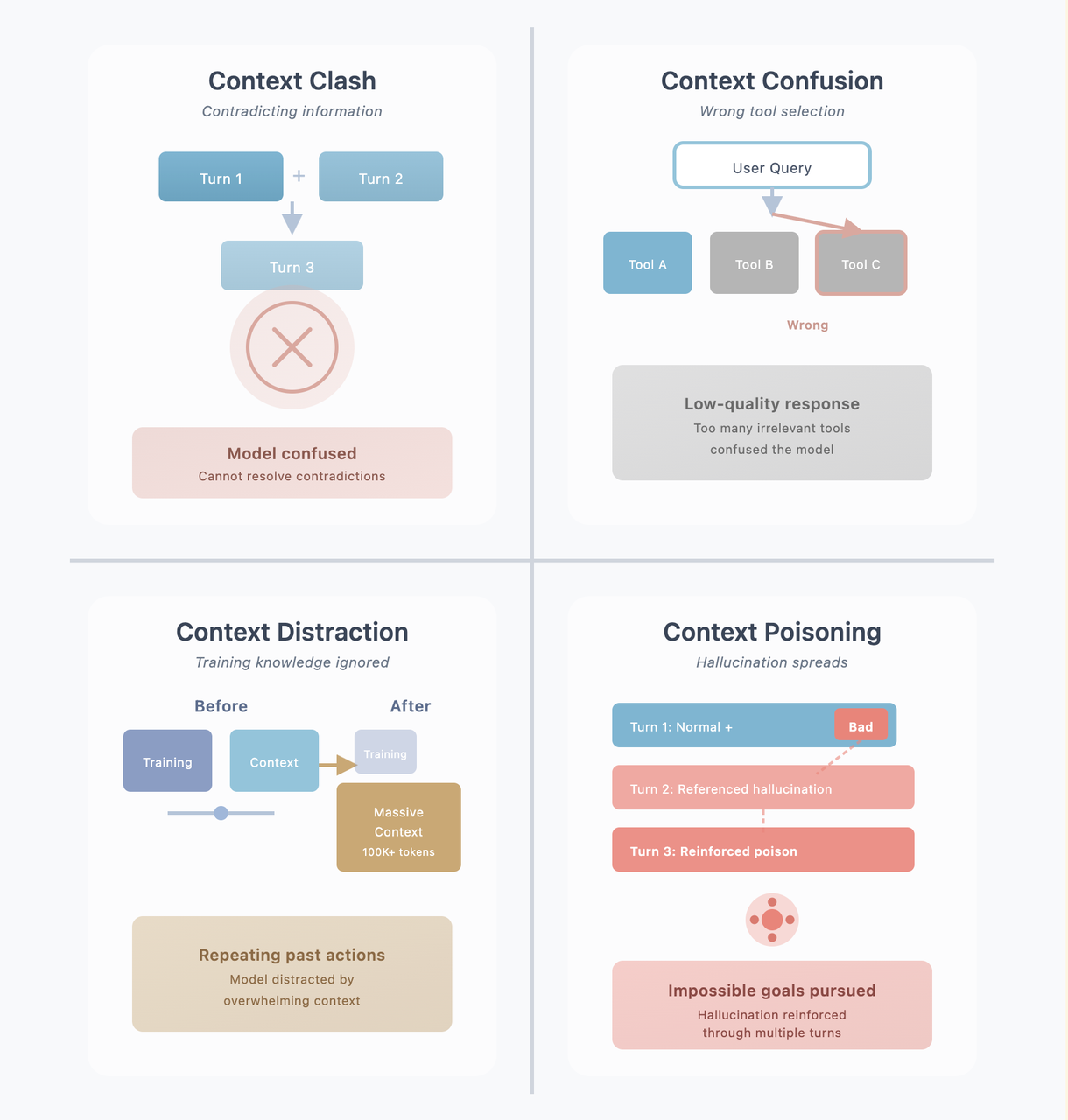
The industry has summarized four common failure modes of long context:
1. Context Clash
Information accumulated in multi-turn conversations contradicts each other. Like saying “I like apples” in the morning and “I don’t like fruits” at noon, the model gets confused: do you like apples or not?
2. Context Confusion
Too much irrelevant information in the context causes the model to choose the wrong tool during tool calling. Similar to a toolbox stuffed with various tools, finding a screwdriver becomes overwhelming.
3. Context Distraction
Massive contextual information suppresses the model’s training knowledge. Like textbooks on a desk being buried under a meter-high pile of comics, the student’s attention is completely drawn away.
4. Context Poisoning
Wrong information is continuously referenced and reinforced in multi-turn conversations. Getting one fact wrong the first time, then subsequent conversations continue to fabricate based on this error, going further and further astray.
02 Context Pruning: The Key to Precise Context Management
To address these long context problems, there are mainly six management strategies: RAG (Retrieval-Augmented Generation), Tool Loadout, Context Quarantine, Context Pruning, Context Summarization, and Context Offloading.
Among these strategies, Context Pruning is particularly crucial because it directly acts on the information input stage.
In RAG systems, we retrieve large amounts of documents from vector databases, most of which are invalid or low-relevance information. Context Pruning aims to precisely filter out irrelevant content after retrieval but before generation, thereby improving generation quality, reducing computational costs, and achieving higher context window utilization.
This is why Context Pruning quality often becomes the core component of RAG optimization.
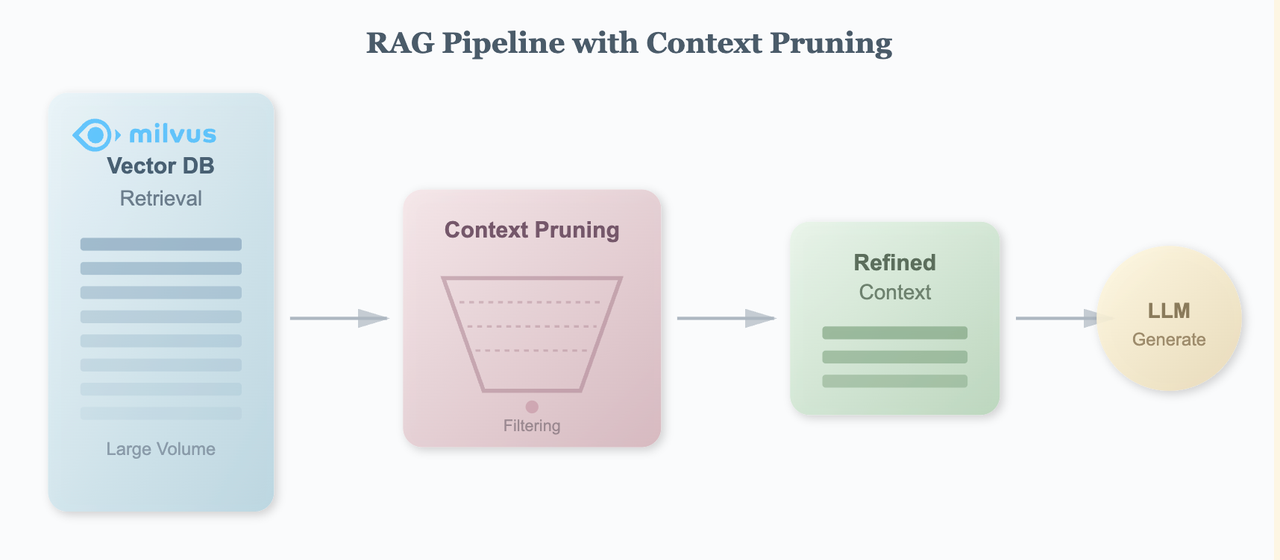
03 Provence: A Practical Context Pruning Model
While researching Context Pruning, I discovered two interesting open-source models: Provence and XProvence, from Naver AI Lab’s work.

Provence’s core functionality is simple: give it a question and a retrieved document, and it will help you filter out truly relevant sentences while removing irrelevant content.
This both speeds up LLM generation and reduces noise interference. Moreover, it’s plug-and-play, compatible with any LLM or retrieval system.
Provence has several impressive characteristics.
First, it understands documents holistically. Unlike some methods that look at each sentence individually, Provence considers all sentences together.
This is important because documents often contain pronouns like “it” or “this.” Looking at a single sentence might not reveal what it’s referring to, but placing it in context makes it clear. This significantly improves pruning accuracy.
Second, it determines how many sentences to keep automatically. You don’t need to tell it “keep 5 sentences” or “keep 10 sentences” - it decides based on specific circumstances. Some questions might need just one sentence, others might need several, and Provence handles both automatically.
Third, it’s highly efficient. On one hand, it’s a lightweight model, much faster than calling large LLMs; on the other hand, it combines pruning and reranking together, adding virtually no extra cost.
Fourth, it has cross-lingual versions. XProvence is the cross-lingual version of Provence, separately trained to support multiple languages including Chinese, English, Korean, etc. The training approach is roughly the same as Provence, just with different datasets.
In implementation, Provence adopts a clever design. Its input is simple: concatenate the question and document together and feed them into the model. This Cross-Encoder architecture allows the model to see both the question and document comprehensively, understanding their relationships.
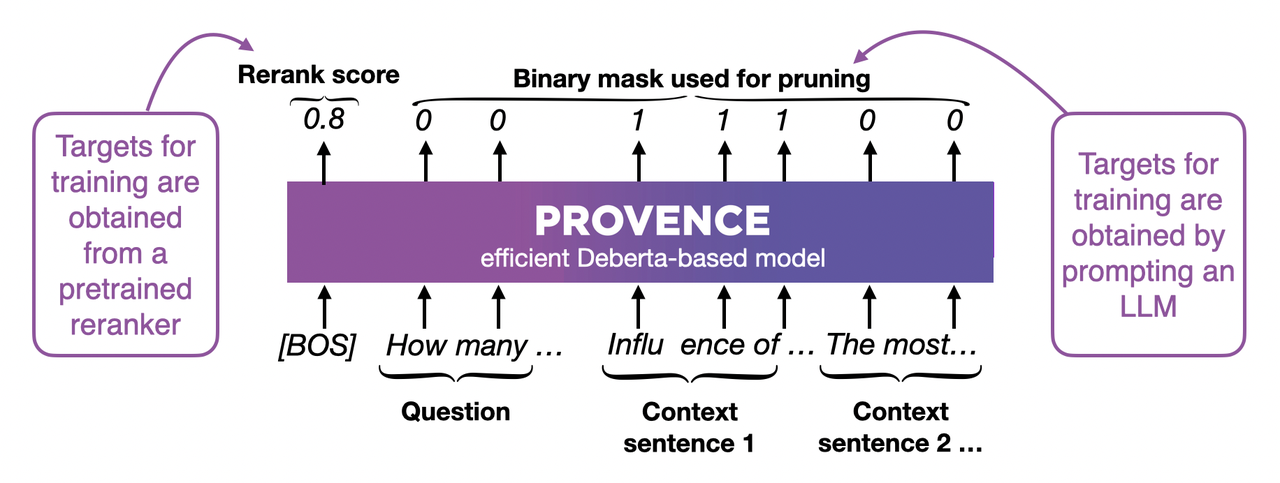
Additionally, Provence is fine-tuned based on DeBERTa. As a lightweight Encoder model, during training it can simultaneously do two things:
-
Score the entire document (Rerank score) - Judge the relevance between the document and question, e.g., 0.8 indicates high relevance
-
Tag each word (Binary mask) - Use 0 and 1 to mark whether each word is relevant, 1 means relevant and should be kept, 0 means irrelevant and can be removed
The model trained this way can both judge document relevance and perform precise sentence pruning: during inference, Provence scores each word, then aggregates by sentence: if a sentence has more words marked as 1 (relevant) than marked as 0 (irrelevant), keep the sentence, otherwise delete it. By adjusting the threshold, you can control the aggressiveness of pruning.
Most importantly, Provence reuses reranking capabilities, so it can be added to RAG pipelines at virtually zero cost.
04 Quantitative Evaluation Experiment
We’ve introduced Provence’s design principles and technical features, but how does it perform in practical applications? How does it compare to other models? To answer these questions, we designed a comprehensive quantitative evaluation experiment comparing pruning quality with other models in real scenarios.
The experiment has two core objectives:
-
Quantitatively evaluate Context Pruning effectiveness: Quantify model pruning quality through standard metrics (Precision, Recall, F1)
-
Test out-of-domain generalization ability: Evaluate model robustness in scenarios with different distributions from training data
For this, we selected three representative models for comparison:
- Provence (naver/provence-reranker-debertav3-v1)
- XProvence (naver/XProvence)
- OpenSearch Semantic Highlight (opensearch-project/opensearch-semantic-highlighter-v1), also a BERT-based pruning model
05 Experimental Design
Dataset Selection: We chose WikiText-2 as our test set. This is a dataset based on Wikipedia articles with diverse article structures, where answers are often scattered across multiple sentences with complex semantic associations.
More importantly, it has significant distributional differences from models’ typical training data while being close to daily business scenarios - exactly the out-of-domain testing environment we wanted.
Question Generation and Annotation: To ensure out-of-domain effects, we used GPT-4o-mini to automatically generate Q&A pairs from WikiText-2 raw corpus. Each sample contains three parts:
- Question (Query): Natural language questions generated from document content
- Document (Context): Complete original document
- Answer Annotation (Ground Truth): Annotate which sentences contain answers (should be kept) and which are irrelevant (should be pruned)
This construction naturally forms a Context Pruning task: models need to identify truly relevant sentences from complete documents based on questions. Answer sentences serve as “positive samples” (should be kept), other sentences as “negative samples” (should be pruned), allowing us to quantify model pruning accuracy through Precision, Recall, F1 and other metrics.
More importantly, questions generated this way won’t appear in any model’s training data, truly reflecting model generalization ability. We generated 300 samples total, covering simple factual, multi-hop reasoning, complex analytical and other question types, approximating real application scenarios as much as possible.
Experimental Process:
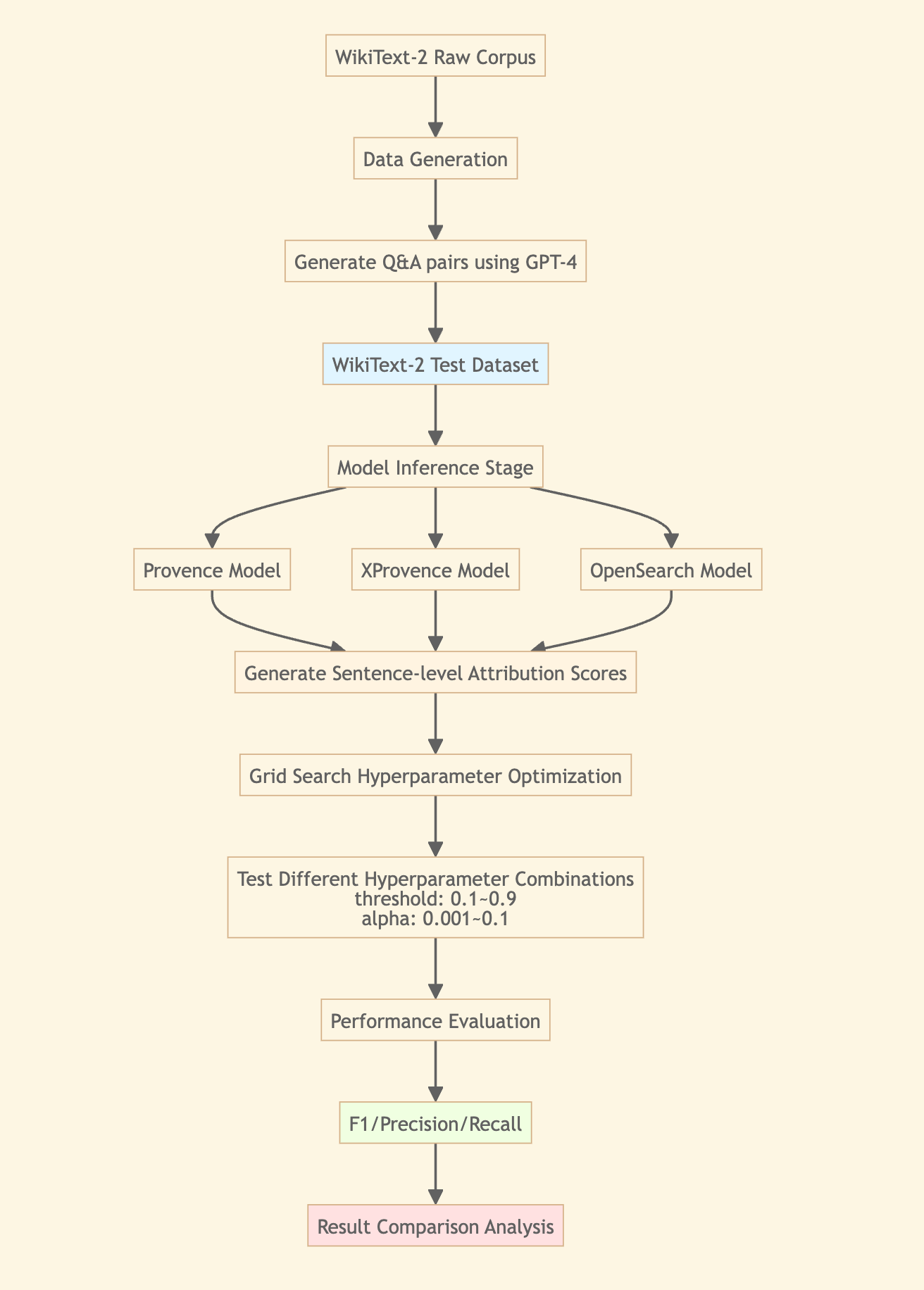
Parameter Optimization: Used Grid Search for hyperparameter optimization on each model. Tested different hyperparameter combinations, ultimately selecting configurations with optimal F1.
06 Experimental Results
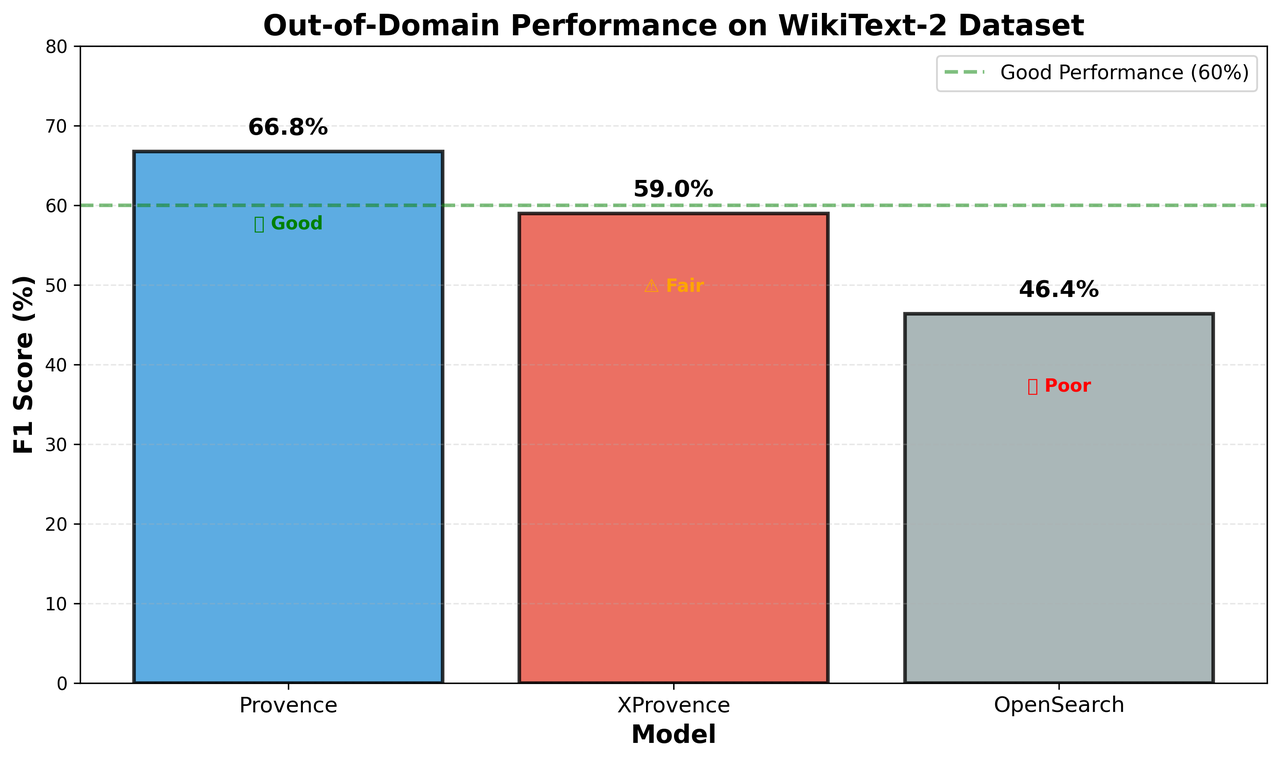
From experimental results, the three models show significant performance differences.
Provence performed best, achieving F1 of 66.76%. Precision (69.53%) and Recall (64.19%) are relatively balanced, showing good out-of-domain generalization ability. Optimal parameters were threshold=0.6, alpha=0.051, indicating the model’s output score distribution is reasonable and threshold setting is relatively intuitive.
XProvence achieved F1 of 58.97%, with somewhat high recall (75.52%) and low precision (48.37%) characteristics. This “better to wrongly select than miss” strategy has advantages in certain scenarios, like medical or legal fields requiring high information completeness. But it also introduces more false positives, reducing precision. Fortunately, XProvence supports multiple languages, compensating for Provence’s limitations in non-English scenarios.
OpenSearch achieved F1 of 46.37% (Precision 62.35%, Recall 36.98%), relatively weaker among the three models, significantly lower than Provence and XProvence, indicating room for improvement in score calibration and generalization ability in out-of-domain scenarios.
07 Context Pruning and Semantic Highlight
Worth mentioning, Context Pruning and an emerging search system feature - Semantic Highlight - are technically the same thing.
Speaking of Highlight, people might be more familiar with traditional Highlight functionality in Elasticsearch - it’s based on keyword matching, using <em> tags to highlight where query terms appear. But this approach is mechanical, only matching literally identical words.
Semantic Highlight is completely different - it’s based on semantic understanding, using deep learning models to judge semantic relevance between text fragments and queries, accurately identifying relevant content even without identical keywords.
Think about it carefully - the essence of both Context Pruning and Semantic Highlight is:
Based on semantic matching between query and context, find the most relevant parts while excluding irrelevant parts.
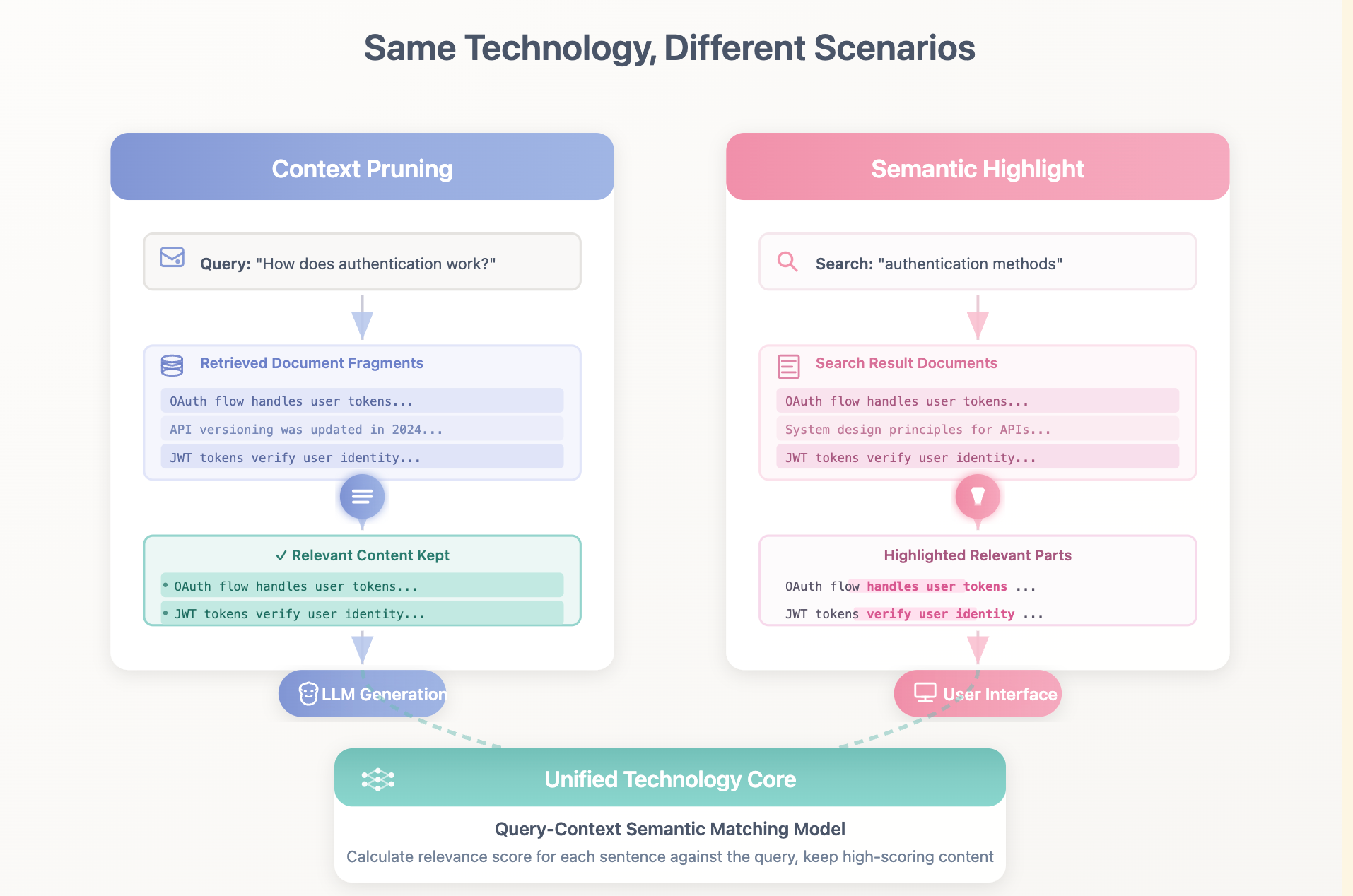
Therefore, they’re essentially the same technology applied in different scenarios.
This means the same model can serve multiple scenarios, improving technology reusability.
With AI’s explosion, semantic understanding and search scenarios are becoming increasingly rich, and Semantic Highlight is gradually becoming an emerging functional requirement.
Based on this understanding, the Milvus team is planning to build in Semantic Highlight functionality. Currently, when Milvus provides vector retrieval, users report that after retrieving large amounts of chunks, it’s difficult to quickly identify which sentences are truly useful.
Therefore, Milvus will subsequently provide model-based Semantic Highlight functionality, seamlessly integrated with vector retrieval pipelines. This way, Milvus will evolve into an intelligent retrieval attribution platform integrating retrieval, reranking, and context pruning, covering RAG optimization, search highlighting, document summarization and other scenarios.
08 Outlook
Context Engineering as an emerging direction still has much exploration space. Whether in algorithm optimization, cross-domain generalization, or deeper integration with RAG pipelines, all deserve further research. The Milvus team will continue following this direction and provide corresponding functional support.