MCP Is Being Abandoned: How Fast Can a 'Standard' Die?
26 Mar 2026 - Cheney Zhang
In mid-March, Perplexity’s CTO Denis Yarats casually dropped a bombshell at the Ask 2026 conference: the company is moving away from MCP internally, going back to REST APIs and CLIs.

The audience barely reacted, but the statement exploded on social media. YC CEO Garry Tan retweeted it with a blunt “MCP sucks honestly” — it eats too much context window, authentication is broken, and he wrote a CLI wrapper in 30 minutes to replace it.
A year ago, this kind of pushback would have been unthinkable. MCP was hailed as the ultimate standard for AI tool integration, ecosystem growth was explosive, and server counts doubled weekly. Now it’s been hyped, overused, and rejected.
So what actually went wrong with MCP?
MCP Is Too Heavy: Context Windows Can’t Handle It
A standard MCP setup consumes roughly 72% of the context window. Someone measured it: three servers (GitHub, Playwright, and an IDE integration) burned through 143K tokens of tool definitions on a 200K-token model. Before the agent even starts working, less than 30% of the space remains.
The cost isn’t just financial. The more noise packed into the context, the worse the model focuses on what matters. With 100 tool schemas sitting there, the agent has to wade through all of them for every single decision.

Researchers call this “context rot.” The data is stark: tool selection accuracy drops from 43% to below 14%. The more tools you add, the worse the agent gets at picking the right one.
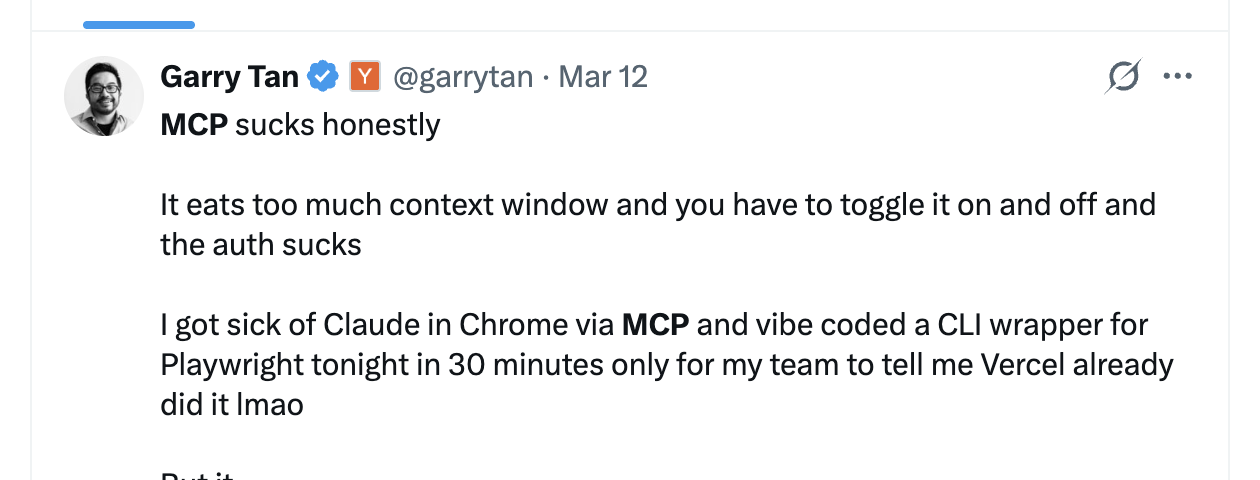
The root cause is MCP’s loading strategy. It dumps all tool descriptions into the session at the start, regardless of whether they’ll be used. This is a protocol-level design choice, not a bug — but the cost scales with the number of tools.
Skills take a different approach: progressive disclosure. At session start, the agent only sees metadata for each Skill — name, one-line description, and trigger conditions. A few dozen tokens total. Only when the agent determines a Skill is relevant to the current task does it load the full content.
In other words, MCP lines up every tool at the door and asks you to pick. Skills hand you an index and let you look things up as needed. With a handful of tools it doesn’t matter. With dozens or hundreds, it matters a lot.
MCP Is Too Dumb: It Just Waits to Be Called
MCP is essentially a tool-calling protocol: how to discover tools, how to invoke them, how to get results. It’s clean for small-scale use, but the “cleanness” is also the limitation — it’s too flat.
No Hierarchy, No Subcommands
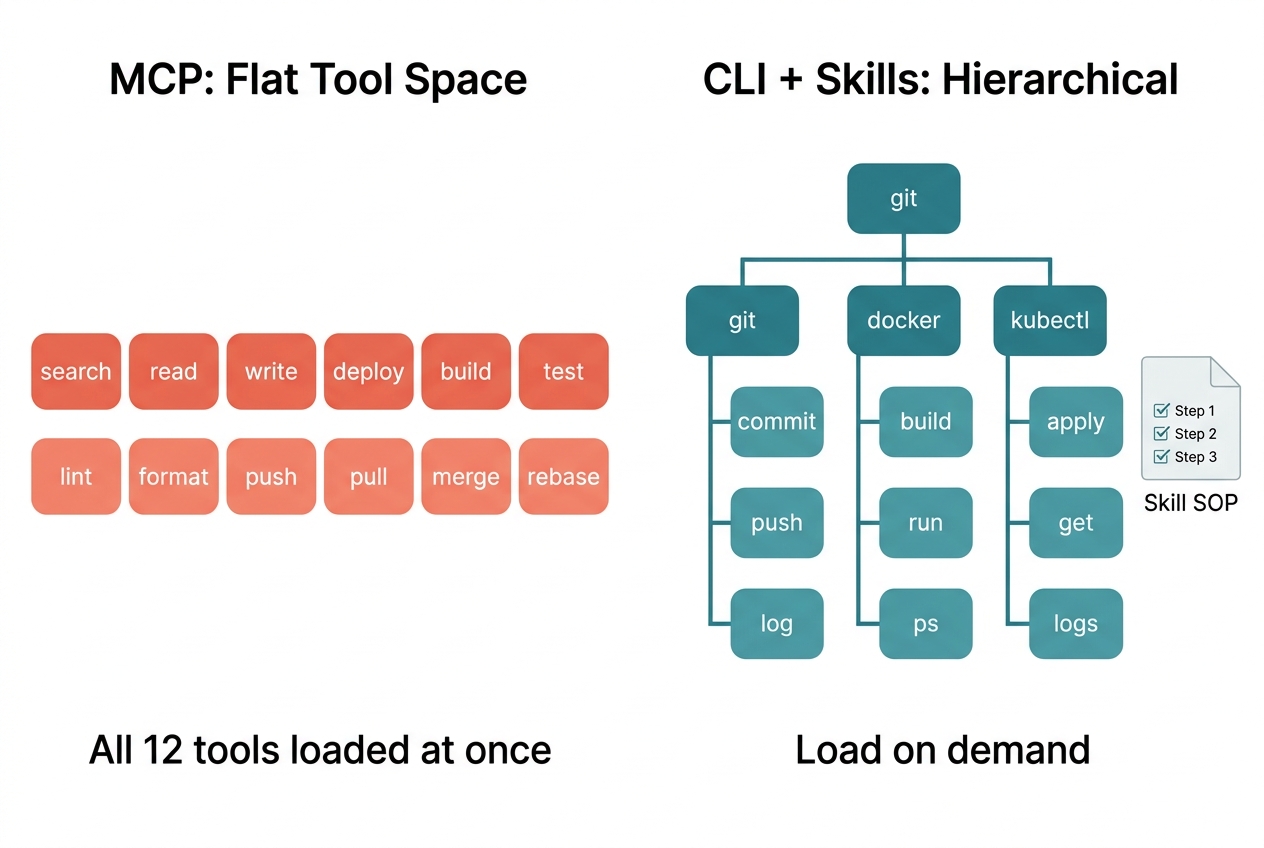
In MCP, a tool is a function signature. No subcommands, no awareness of session lifecycle, no knowledge of where the agent is in its workflow. Tools just sit there, waiting to be called.
CLI tools are fundamentally different. A CLI naturally has subcommands — git commit, git push, git log are completely different behavior paths. An agent can run --help first, explore what’s available, and expand as needed without stuffing all parameter docs into context at once.
No SOPs, No Guidance for the Agent
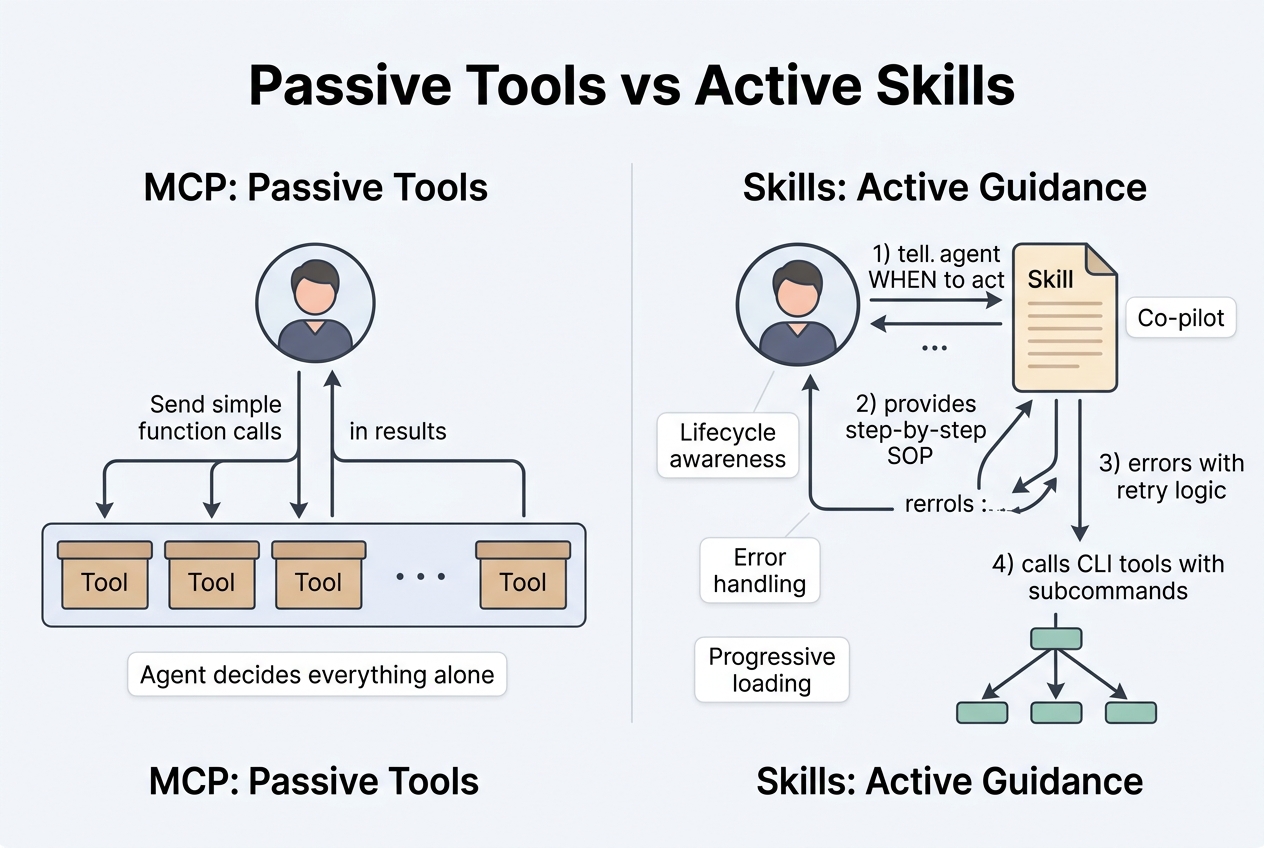
Agent Skills have a completely different philosophy. A Skill is essentially a markdown file containing an SOP: what to do first, what to do next, how to retry on failure, when to notify the user. The agent doesn’t get an isolated tool — it gets a complete operational playbook.
MCP tools can only passively wait for the agent to call them. Skills can actively participate in the agent’s workflow: when to trigger, what to prepare before and after, how to handle errors — all of this can be specified in the Skill.
Can’t Reuse the Agent’s LLM
This one hits close to home. Six months ago, we built the claude-context MCP project to provide contextual code retrieval for Claude Code. When a user asked a question, MCP retrieved relevant conversation fragments from a Milvus vector database and fed them back into the context.
Once the feature was working, the problem became obvious: out of the top 10 retrieved results, maybe 3 were actually useful. The other 7 were noise. Without filtering, dumping everything back to the outer agent hurt response quality — sometimes the irrelevant history fragments actively misled it.
I tried several approaches. Give everything to the agent? Too much noise, answer quality dropped visibly. Add reranking inside the MCP server? Small models weren’t accurate enough, and the score threshold (0.7? 0.8?) varied wildly across scenarios. Use a large model? Sure, but the MCP server is a separate process — it can’t access the outer agent’s LLM. I’d need to configure a separate LLM client, a separate API key, and separate invocation logic inside the server.
That’s when I started wondering: could there be a way to let the outer agent’s LLM participate directly in the tool’s internal decisions? Let the agent itself judge which retrieval results are worth keeping, without setting up a parallel system.
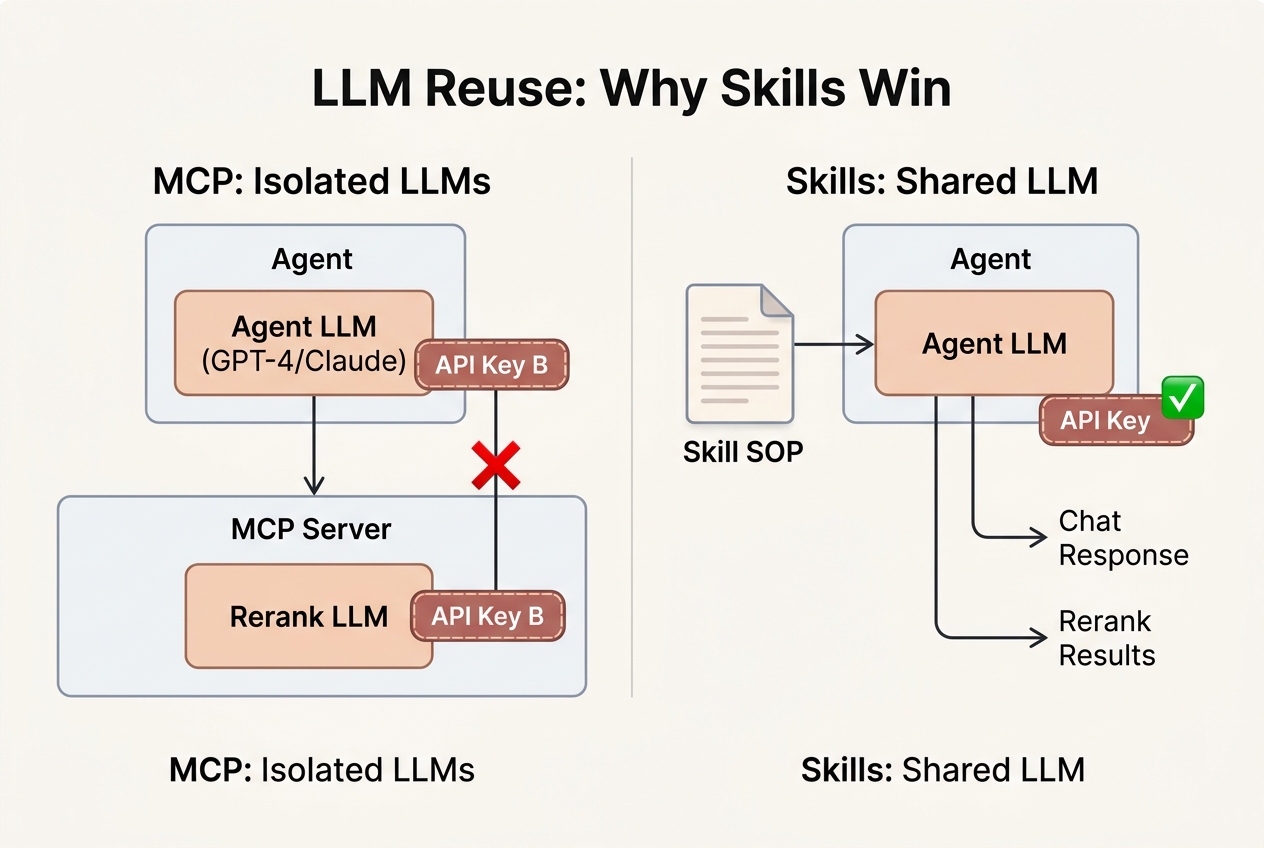
It turned out Skills solve exactly this problem. A retrieval Skill can be structured as: first run vector search for top 10, then let the agent’s own LLM judge relevance, filter noise, and return only useful results. No extra model, no extra API key — the agent handles it all.
Our later project memsearch used this approach in its Claude Code extension. The memory recall Skill runs in a dedicated subagent with three-layer progressive retrieval: vector search for rough filtering, the agent deciding which results are worth expanding, and if necessary, diving into raw conversation records. The agent’s LLM participates throughout — what to keep, what to discard, whether to dig deeper — all its own decisions. Only the curated results go back to the main agent; all the search noise and raw data stay invisible to the main conversation.
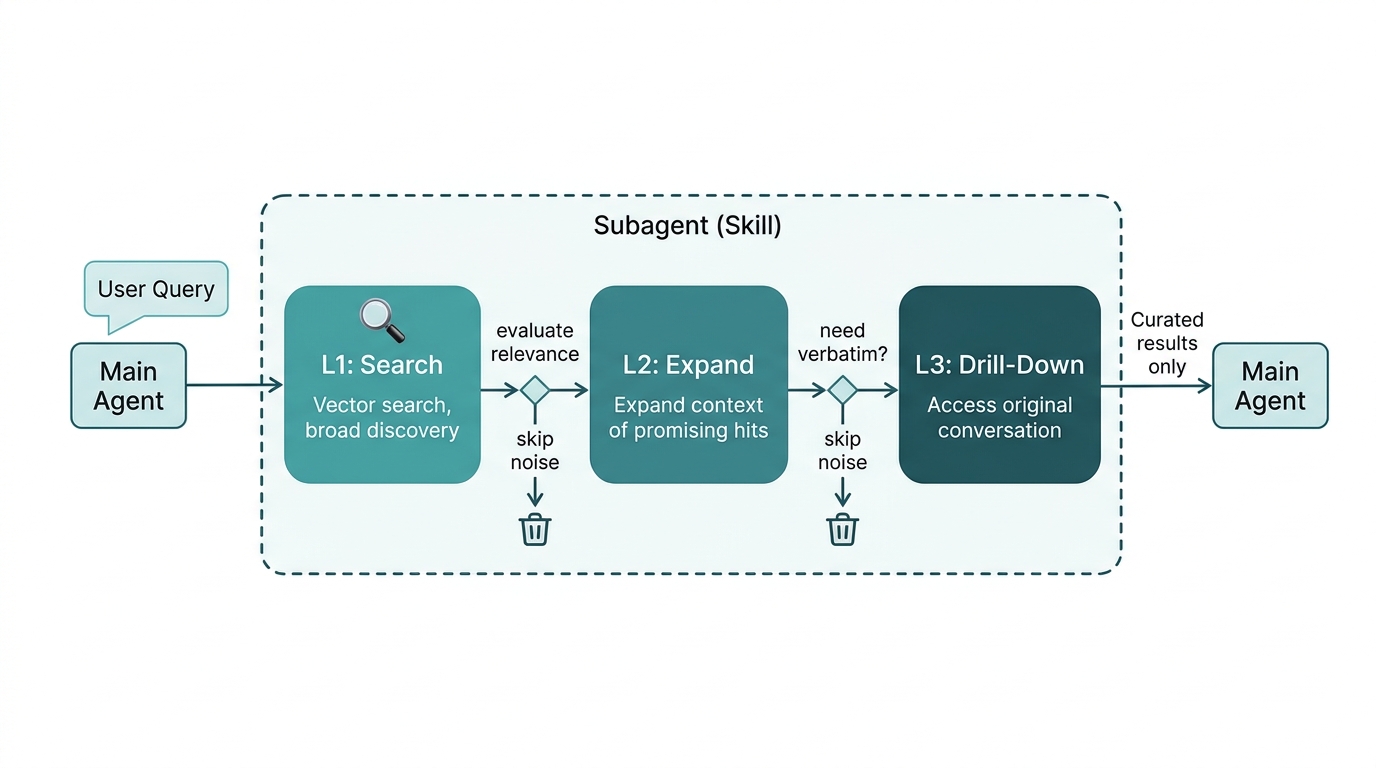
MCP can’t do any of this. There’s a process boundary between server and agent — the server can’t use the agent’s LLM, and the agent can’t control what happens inside the server. Fine for simple CRUD tools, but the moment a tool needs to make judgment calls or filter results, that isolation becomes a wall.
But Does MCP Deserve to Die?
A Hacker News thread titled “When does MCP make sense vs CLI?” saw top comments overwhelmingly favoring CLI: “CLI tools are like precision instruments,” “CLIs also feel snappier than MCPs.” But it’s not that simple.
MCP has been donated to the Linux Foundation, has over 10,000 active servers, and SDK downloads hit 97 million per month. An ecosystem that large doesn’t just die overnight.
Some developers take a more moderate view: Skills are like a detailed recipe that helps you solve problems better; MCP is the tool that helps you solve them. Both have their place.
Fair point, but here’s the question: if the recipe itself can direct the chef on which tools to use and how, do you still need a separate “tool distribution protocol”?
It depends on the scenario. MCP over stdio — the mode most developers run locally — has the most issues: unstable inter-process communication, messy environment isolation, heavy token overhead. You can find a better alternative for almost every aspect.
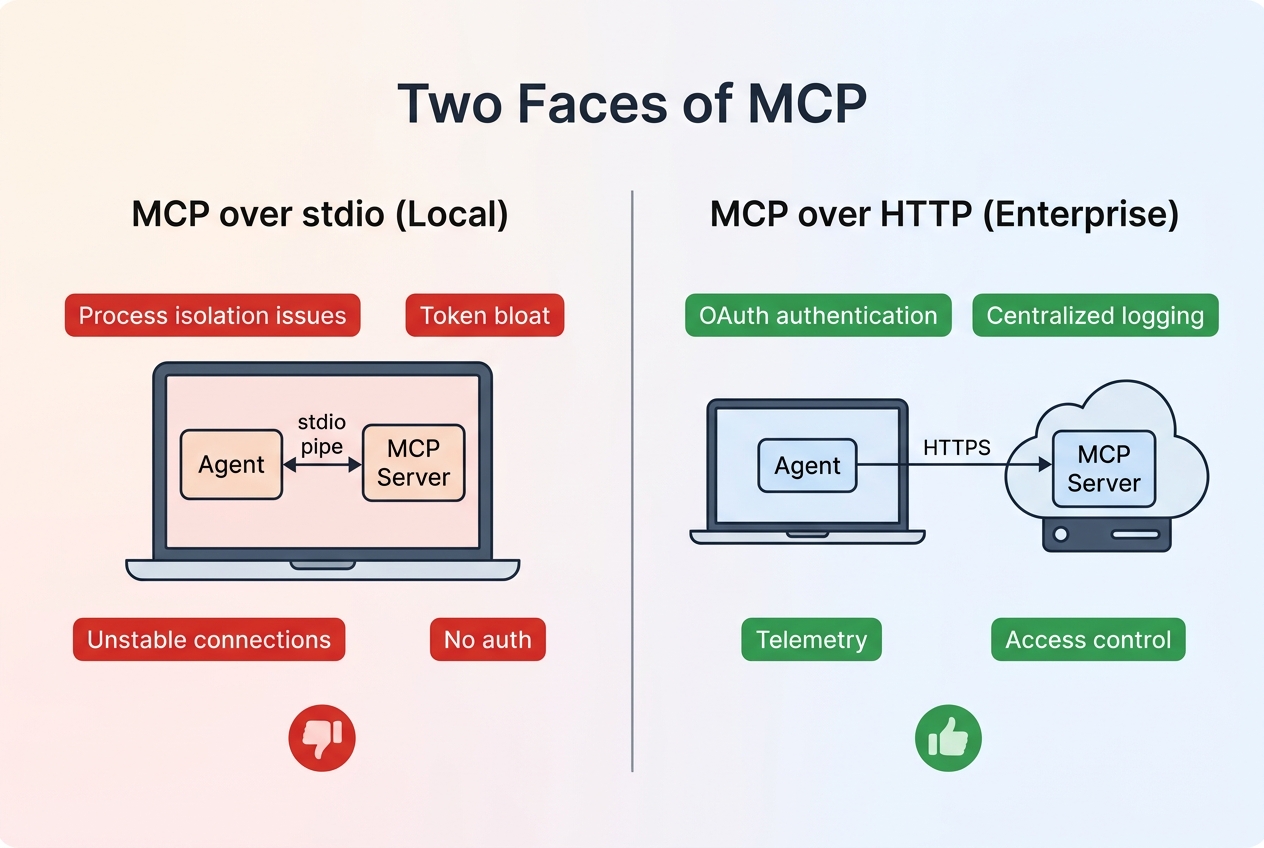
But MCP over HTTP is a different story. Enterprise tool platforms need unified permission management, centralized OAuth authentication, standardized telemetry and logging — things that scattered CLI tools genuinely struggle to provide. MCP’s centralized architecture has real value here.
What Perplexity abandoned was mainly the stdio usage. Denis Yarats emphasized they were deprioritizing it “internally” — not that the entire industry should follow suit. But nuance gets lost in transmission. “Perplexity drops MCP” spreads far better than “Perplexity deprioritizes MCP over stdio for internal tool integration.”
At the end of the day, MCP took off because it solved a real problem: previously every AI application had to write its own tool-calling logic, leading to severe fragmentation. MCP provided a unified interface, launched at the right time, and the ecosystem snowballed. It wasn’t until more people hit production pain points that the pushback started.
MCP probably won’t disappear. It will retreat to where it fits — enterprise tool platforms, scenarios requiring centralized governance. But the claim that “every agent should use MCP” no longer holds up.
What’s Next
As Skills move toward open standardization, toolchains across the industry are catching up. Progressive disclosure as a concept has been broadly accepted — only the final form remains undefined.
The most pragmatic combination right now is CLI + RESTful + Skills: CLIs for everyday operations, RESTful APIs for external system integration, Skills for agent behavioral knowledge. MCP hasn’t vanished from this picture, but its position has shifted — from “the standard” to “one option among several.”
For developers, this might actually be a good thing. As tools multiply, no single protocol can cover every scenario. Knowing when to use what beats clinging to one standard.
MCP left the industry with a valuable question: what kind of tool interface do agents actually need? The answer is slowly taking shape — it’s just no longer something a single protocol can provide.